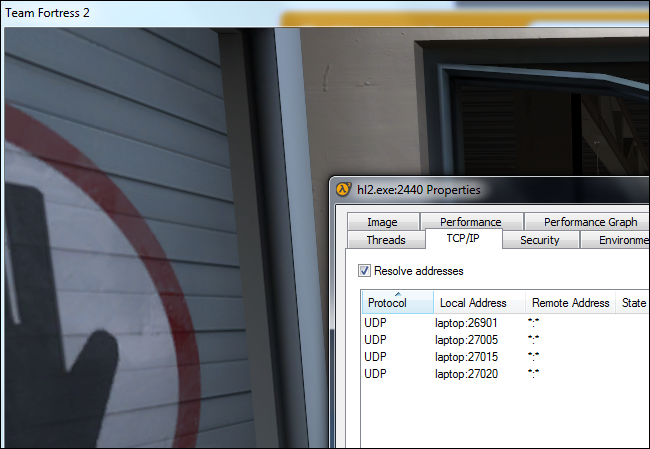
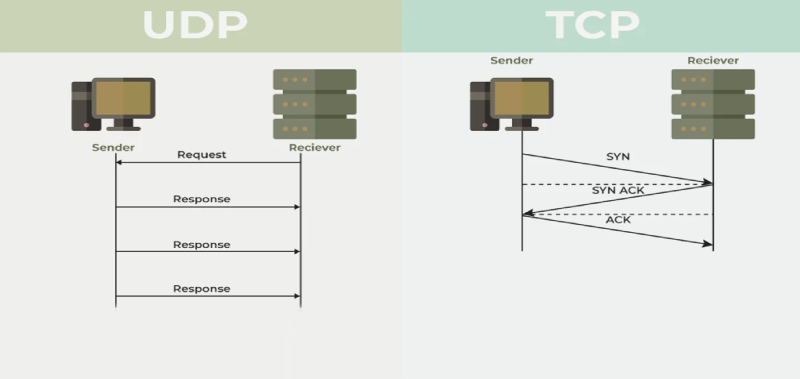
هکر ها، با هدف های مختلفی از جمله رمزگذاری داده ها و باج گیری، رخنه اطلاعات، ایجاد اختلال در عملکرد شبکه و… دست به حملات سایبری می زنند. مجموعه فورتی گارد (FortiGuard)، یک راهکار یکپارچه است که شامل فیچیر های امنیتی گسترده ادغام شده فورتی نت می شود و امکان تامین هوشمندانه امنیت را فراهم می سازد.
فورتی گارد (FortiGuard)
فورتی گارد (FortiGuard)، یک سرویس پیشرفته ارائه شده توسط کمپانی فورتی نت است که مثل سایر سرویس های فورتی نت، با هدف تامین امنیت سایبری سازمان ها طراحی شده است. با استفاده از سرویس های فورتی گارد، امکان پیشگیری از بدافزار ها، حملات سایبری، رخنه اطلاعات، رمزگذاری داده و سایر تهدیدات سایبری، فراهم می شود تا امنیت شبکه های سازمانی برقرار شود.
به طور خلاصه باید بدانید فورتیگارد مجموعهای از سرویسهای امنیتی است که توسط شرکت Fortinet ارائه میشود. این سرویسها بهطور خاص برای محافظت از شبکهها و دادههای سازمانها در برابر تهدیدات سایبری طراحی شدهاند. سرویسهای فورتیگارد بهصورت یکپارچه با فایروالهای فورتیگیت (FortiGate) کار میکنند و شامل طیف گستردهای از ویژگیهای امنیتی پیشرفته هستند.
سرویسهای اصلی فورتیگارد عبارتند از:
فیلتر محتوای وب (Web Filtering): مسدود کردن وبسایتهای مخرب و غیرمجاز.
آنتیویروس (Antivirus): شناسایی و جلوگیری از بدافزارها و ویروسها.
پیشگیری از نفوذ (IPS – Intrusion Prevention System): تشخیص و جلوگیری از حملات به شبکه.
کنترل برنامهها (Application Control): مدیریت دسترسی به نرمافزارها و برنامههای مختلف.
ضد هرزنامه (Anti-Spam): مسدود کردن ایمیلهای ناخواسته و هرزنامهها.
بهروزرسانی بلادرنگ (Real-Time Updates): بهروزرسانی لحظهای برای مقابله با تهدیدات جدید.
کنترل دستگاهها (Device Control): مدیریت و محدود کردن دسترسی به دستگاههای متصل به شبکه.
بهتر است بدانید، فورتیگارد به سازمانها کمک میکند تا با کاهش ریسکها و شناسایی تهدیدات جدید، امنیت شبکه خود را به سطح جدیدی ارتقا دهند و از اطلاعات محرمانه خود در برابر تهدیدات محافظت کنند.
عملکرد فورتی گارد چگونه است؟
سیستم امنیتی فورتی گارد، از شبکه های سازمانی در برابر بروزترین و جدیدترین تهدیدات سایبری در سطح محتوا (content-level) مانند ویروس ها و جاسوس افزارها، محافظت می کند تا یک امنیت تضمینی را ارائه دهد. همچنین فورتی گارد برای انجام این کار، از موتور های پیشرفته ای برای تشخیص تهدیدات استفاده می کند تا از نفوذ بدافزار ها و … جلوگیری کند.
عملکرد فورتیگارد بهصورت مداوم با جمع آوری اطلاعات از شبکههای مختلف بهروزرسانی میشود و به صورت خودکار امضاهای جدید امنیتی را ایجاد میکند. این امضاها به فورتیگیت و دیگر محصولات فورتینت منتقل میشوند تا تهدیدات مانند ویروسها، بدافزارها و حملات شبکهای شناسایی و مسدود شوند. فورتیگارد به این ترتیب یک سیستم امنیتی پویا و خودکار ایجاد میکند که بهطور مستمر می تواند تهدیدات جدید را شناسایی کرده و امنیت شبکه را در برابر حملات پیچیده بهروزرسانی میکند.
آزمایشگاه فورتی گارد چیست؟
صد ها متخصص تحقیقاتی در آزمایشگاه های فورتی گارد مشغول به کار هستند که به طور میانگین، هر کدام بیش از 16 سال تجربه در تحقیقات و پاسخ به تهدیدات دارند؛ آن ها حفاظت پیشرفته و امنیت سایبری بالایی را برای مشتریان فورتی نت فراهم کنند و این کار را با کشف تهدیدات نوظهور و توسعه اقدامات موثر برای محافظت از سازمان ها انجام می دهند.
فورتی گارد به دلیل داشتن بیش از 650 اکتشاف روز صفرشناخته شده است و این، رکوردی است که با هیچ شرکت امنیت دیگری قابل مقایسه نیست. ترکیبی جامع از تحقیقات داخلی، اطلاعات و داده ها، یادگیری ماشینی و تکنولوژی های هوش مصنوعی باعث شده است که راهکارهای امنیتی فورتی نت، در تستهای امنیت سازمان هایی مانند آزمایشگاههای NSS، بولتن ویروس، آزمایشگاههای ICSA، AV Comparatives و… امتیاز بالایی کسب کنند.
مزایای فورتی گارد
استفاده از سرویس های فورتی گارد مزایای بسیاری برای شبکه ها دارد که در ادامه به اصلی ترین آن ها می پردازیم.
پیشگیری از حملات سایبری موفقیت آمیز
تنوع آنتی ویروس های FortiGuard مانند NGFW و sandboxing
کاهش خطر نفوذ به اطلاعات و یا ایجاد اختلال در داده ها
جلوگیری از ورود پیچیده ترین بدافزار ها به شبکه
دریافت آنی امضای تهدیدات جدید سایبری که توسط FortiGuard Labs ارائه می شوند
صرفه جویی در هزینه های مدیریتی و عملیاتی، زمان و منابع
توانایی شناسایی هزاران نسخه از بدافزار های فعلی و آینده با یک single signature
جمع بندی
در پایان، بهتر است بدانید که تهدیدات جدید سایبری، در هر لحظه از هر روز ایجاد و پدیدار می شوند که سازمان ها، باید همیشه آماده دفاع از شبکه خود در برابر این حوادث نوظهور باشند؛ داشتن دانش گسترده ای از تهدیدات سایبری و قابلیت واکنش سریع در سطح های مختلف، پایه و اساس ایجاد یک امنیت شبکه موثر است. سرویس های فورتی گارد، یکی از بهترین راهکارهای تامین، حفظ و تقویت امنیت شبکه سازمانی به حساب می آید که اهمیت بالای آن به دلیل داشتن تحقیقات و هوش تهدید آزمایشگاه های فورتی گارد برای محافظت از شبکه سازمانی است.
سوالات متداول
سرویس فورتی گارد چیست؟
سرویس های امنیتی فورتی گارد به محافظت از شبکه در برابر حملات مبتنی بر فایل می پردازند؛ برای مثال می توان به سرویس های آنتی ویروس فورتی گارد اشاره کرد که از تهدیداتی همچون بدافزارها و از دست دادن داده (DLP) پیشگیری می کنند.
کاربرد فورتی گارد چیست؟
فورتی گارد برای شناسایی و بلاک کردن هر ترافیکی که آسیب پذیری های شبکه را مورد هدف قرار می دهد استفاده می شود؛ شناسایی و پاسخ به حمله، از طریق سرویس تشخیص امضای IPS FortiGuard و یک کنترل کننده خودکار اتفاق می افتد که در نهایت، از طریق FortiAnalyzer حوادث پیش آمده گزارش می شوند.
آیا میتوان فورتی گارد را حذف یا غیر فعال کرد؟
اگر سازمان شما از سرویس های فورتی گارد استفاده می کند، نمی توانید بدون کنترل های سطح اداری (administrative level controls) آن را حذف یا غیرفعال کنید؛ باید از شبکه یا دستگاه دیگری استفاده کنید.
فورتی گارد چه چیزهایی را بلاک می کند؟
سرویس فیلترینگ URL فورتی گارد، حفاظتی جامع از تهدیدات را ارائه می دهد تا از بدافزار ها، سرقت اطلاعات کاربری، حملات فیشینگ، حملات سایبری و… جلوگیری شود.
چرا باید از فورتی گارد استفاده کنیم؟
شما می توانید از سرویس های فورتی گارد برای محافظت از سازمان خود استفاده کنید چرا که این سرویس ها، به دلیل جلوگیری از تهدیدات سایبری، از بهترین روش های تامین امنیت شبکه به حساب می آیند.
بهترین VPN رایگان برای فورتی گارد چیست؟
Touch VPN، یک سرویس وی پی ان رایگان است که امکان استفاده نامحدودی را در اختیار کاربران قرار می دهد و هیچگونه محدودیت سرعتی یا حجمی ندارد؛ همچنین فقط با یک کلیک ساده فعال می شود.
حتما برای شما هم اتفاق افتاده است که گاه قصد داشته اید تا فقط چند دقیقه ای پست های اپلیکیشنی مثل اینستاگرام را چک کنید ولی یهو وقتی به خودتان آمدید متوجه شده اید که چندین ساعت است که گرم بازدید از ریلزهایی هستید که دقیقا بر مبنای خط فکری شماست؛ انقدر مجذوب پست ها شده اید که گذر زمان را فراموش کرده اید. آیا تا به حال به دلیل اصلی این موضوع فکر کرده اید؟ آیا فقط یه اتفاق تصادفی است یا کاسه ای زیر نیم کاسه است؟ باید بگویم که اتفاق عجیبی در کار نیست و همه اینها طبق برنامه ریزی پیش می رود. پایه و اساس همه این موضوعات و نوآوری ها هوش مصنوعی است. در ادامه این مطلب با ما همراه باشید تا به صورت کلی و جامع به بررسی این موضوع بپردازیم.
هوش مصنوعی چیست؟
هوش مصنوعی (Artificial intelligence) به اختصار AI شاخه ای از تکنولوژی است که کامپیوترها و ماشینها را قادر میسازد تا یادگیری، درک، حل مسئله، تصمیمگیری، خلاقیت و استقلال انسان را شبیهسازی کنند. اپلیکیشن ها و دستگاه های مجهز به هوش مصنوعی می توانند اشیا را دیده و شناسایی کنند، زبان انسان ها را بفهمند و به آن پاسخ دهند، اطلاعات و تجربیات جدید بیاموزند، توصیه های دقیقی را به کاربران و کارشناسان ارائه دهند، به طور مستقل عمل کنند و نیاز به هوش یا مداخله انسانی نداشته باشند (از نمونه های کلاسیک هوش مصنوعی می توان خودروهای خودران را نام برد.)
در سال 2024، بیشتر محققان و متخصصان هوش مصنوعی بر پیشرفتهای هوش مصنوعی مولد (generative AI) متمرکز شدهاند، فناوریای که میتواند متن، تصاویر، ویدیو و سایر محتواهای اورجینال تولید کند. برای درک کامل هوش مصنوعی مولد، ابتدا باید تکنولوژی هایی را که ابزارهای هوش مصنوعی مولد بر اساس آن ساخته شده اند را بررسی کرد: یادگیری ماشین و یادگیری عمیق.
یادگیری ماشین
یادگیری ماشین (Machine Learning) زیر مجموعه ای از هوش مصنوعی است که دقیقاً در زیر آن قرار می گیرد، و شامل ایجاد مدلهایی با استفاده از آموزش الگوریتمی برای پیشبینی یا تصمیمگیری بر اساس دادهها است؛ طیف وسیعی از تکنیکها را در بر می گیرد و کامپیوترها را قادر میسازد بدون اینکه برای انجام کار خاصی برنامهریزی شده باشند، از دادهها بیاموزند و استنتاج کنند.
یکی از محبوب ترین انواع الگوریتم های یادگیری ماشین، شبکه عصبی (یا شبکه عصبی مصنوعی) است و از ساختار و عملکرد مغز انسان الگو برداری شده اند. ساده ترین شکل یادگیری ماشین، یادگیری تحت نظارت نامیده می شود که شامل استفاده از مجموعه داده های برچسب گذاری شده برای آموزش الگوریتم هایی جهت طبقه بندی داده ها و یا پیش بینی دقیق نتایج است.
یادگیری عمیق
یادگیری عمیق (Deep Learning) زیرمجموعه ای از یادگیری ماشین است که از شبکه های عصبی چند لایه به نام شبکه های عصبی عمیق استفاده می کند که قدرت تصمیم گیری پیچیده مغز انسان را با دقت بیشتری شبیه سازی می کند.
شبکههای عصبی عمیق شامل یک لایه ورودی، یک لایه خروجی و حداقل سه یا گاه تا صدها لایه پنهان هستند؛ شبکههای عصبی مورد استفاده در مدلهای کلاسیک یادگیری ماشین معمولاً فقط یک یا دو لایه پنهان دارند. از آنجایی که یادگیری عمیق نیازی به مداخله انسانی ندارد، یادگیری ماشین را در مقیاس فوق العاده ای امکان پذیر می کند. یادگیری عمیق شامل یادگیری بدون نظارت، یادگیری نیمه نظارتی، یادگیری خود نظارتی، یادگیری تقویتی و یادگیری انتقالی است.
هوش مصنوعی مولد
هوش مصنوعی مولد (Generative AI) به مدلهای یادگیری عمیقی اشاره دارد که توانایی تولید محتوای اورجینال پیچیده (مانند متون طولانی، تصاویر با کیفیت بالا، ویدیو ها یا صداهای واقعی و غیره) را دارند.
مدل های مولد سال ها در آمار برای آنالیز داده های عددی مورد استفاده قرار گرفته اند. اما در طول دهه گذشته، برای آنالیز و تولید انواع داده های پیچیده تر تکامل یافتند. این تکامل با ظهور سه نوع مدل یادگیری عمیق پیچیده همزمان شد: رمز گذارهای خودکار متغیر، مدل های گسترشی، ترانسفورماتورها (مدلهای ترانسفورماتور).
هوش مصنوعی مولد چگونه کار می کند؟
به طور کلی، هوش مصنوعی مولد در سه مرحله عمل می کند:
آموزش، برای ایجاد یک مدل پایه.
تنظیم، برای تطبیق مدل با یک اپلیکیشن خاص.
تولید، ارزیابی و تنظیم بیشتر، برای بهبود دقت.
مزایای هوش مصنوعی
هوش مصنوعی مزایای متعددی را در صنایع و اپلیکیشن های مختلف ارائه می دهد. برخی از رایج ترین مزایای از این قرار هستند:
اتوماسیون کارهای تکراری؛ خودکار سازی کارهای معمول، تکراری و اغلب خستهکننده ی دنیای دیجیتال مانند جمعآوری دادهها و کارهای فیزیکی نظیر تولید.
خودکار سازی کارها موجب می شود که وقت نیروی متخصص صرف اموری با ارزش بالاتر و خلاقانه تر شود.
یافتن بینش بیشتر و سریعتر از داده ها.
بهبودی تصمیم گیری. امکانپذیری پیشبینیهای سریعتر، دقیقتر و تصمیمگیریهای قابل اعتماد و مبتنی بر داده.
خطاهای انسانی کمتر. کاهش خطاهای انسانی از طریق راهنمایی افراد، شناسایی خطاهای احتمالی قبل از وقوع و خودکارسازی کامل فرآیندها بدون دخالت انسان؛ برای مثال در حوزه مراقبتهای بهداشتی می توان جراحی رباتیک که با هوش مصنوعی هدایت می شود را نام برد.
از آنجاییکه الگوریتم های یادگیری ماشین در معرض داده های فراوانی قرار می گیرند، می توانند به طور مداوم دقت خود را بهبود بخشند، خطاها را بیشتر کاهش دهند و از تجربه یاد بگیرند.
دسترسی تمام وقت. فعالیت و دسترسی در تمام ساعات شبانه روز و ثبات عملکردی؛ ابزارهایی نظیر رباتهای چت هوش مصنوعی یا دستیاران مجازی.
کاهش خطرات فیزیکی. خودکار سازی امور خطرناک بمانند کنترل حیوانات، جابجایی مواد منفجره، انجام وظایف در اعماق اقیانوس ها، ارتفاعات بالا یا در فضای های روباز.
موارد استفاده از هوش مصنوعی
کاربردهای هوش مصنوعی در دنیای واقعی بسیار زیاد هستند. چند نمونه از موارد استفاده در صنایع مختلف را در ذیل بررسی می کنیم:
تجربه مشتری، خدمات و پشتیبانی
شرکت ها می توانند چت ربات های مبتنی-بر-هوش مصنوعی و دستیاران مجازی را برای رسیدگی به سوالات مشتریان، تیکت های پشتیبانی و موارد دیگر پیاده سازی کنند. این ابزارها از پردازش زبان طبیعی (NLP) و قابلیتهای هوش مصنوعی مولد برای درک و پاسخ به سوالات مشتری در مورد وضعیت سفارش، جزئیات محصول و سیاستهای بازگشت کالا استفاده میکنند.
رباتهای چت و دستیارهای مجازی پشتیبانی دائمی ارائه میکنند، پاسخهای سریعتری به سؤالات متداول ارائه میکنند، زمان نیروی انسانی برای تمرکز در انجام کارهای سطح بالاتر را خالی می کنند و به مشتریان خدمات سریعتر و ثابتتری ارائه میدهند.
کشف تقلب
الگوریتمهای یادگیری ماشین و یادگیری عمیق میتوانند الگوهای تراکنشها را آنالیز کنند و ناهنجاریها را تعیین کنند؛ از جمله این موارد می توان هزینهها یا مکانهای ورود به سیستم غیرمعمول که نشاندهنده تراکنشهای جعلی هستند را نام برد. این امر به سازمانها امکان میدهد به کلاهبرداری های احتمالی سریعتر واکنش دهند و با محدودسازی تأثیر آن، آرامش بیشتری برای خود و مشتریان فراهم آورند.
بازاریابی شخصی
خردهفروشان، بانکها و سایر شرکتهایی که با مشتری ها در ارتباط هستند، میتوانند از هوش مصنوعی برای ایجاد تجربیات شخصی سازی شده مشتریان و کمپینهای بازاریابی استفاده کنند که این امر نیز خشنودی مشتریان را بدنبال خواهد داشت، فروش را بهبود خواهد بخشید و از ریزش آن جلوگیری خواهد کرد.
الگوریتمهای یادگیری عمیق بر اساس دادههای قبلی (تاریخچه) و رفتارهای خرید مشتری، میتوانند محصولات و خدماتی را که مشتریان احتمالاً طالب آنها هستند را توصیه کنند و حتی نسخههای شخصیسازی شده و پیشنهادهای ویژه برای مشتریان خاص را بصورت آنی ایجاد کنند.
منابع انسانی و استخدام
پلتفرمهای استخدام مبتنی بر هوش مصنوعی میتوانند با بررسی رزومه، تطبیق توانایی های کارجویان با شرح وظایف شغلی و حتی انجام مصاحبههای اولیه با استفاده از آنالیز ویدئویی، استخدام را سادهتر کنند. این ابزارها می توانند به طور چشمگیری کوهی از کاغذبازی های اداری مرتبط با شمار زیاد کارجویان را کاهش دهند.
همچنین با کاهش زمان پاسخگویی و استخدام میتوانند تجربه کارجویان را بهبود بخشند (چه آن دسته که استخدام می شوند و چه آن دسته که درخواستشان رد می شود).
توسعه و نوسازی اپلیکیشن
ابزارهای تولید کد هوش مصنوعی مولد و ابزارهای اتوماسیون میتوانند وظایف کدگذاری تکراری مرتبط با توسعه اپلیکیشن ها را سادهسازی بکنند و مهاجرت و نوسازی (تغییر قالببندی و تبدیل مجدد) اپلیکیشن های قدیمی در مقیاس های مناسب را سرعت بخشند. این ابزارها می توانند کارها را سرعت بخشند، به اطمینان از ثبات کد کمک کنند و خطاها را کاهش دهند.
تعمیر و نگهداری پیشگیرانه
مدلهای یادگیری ماشینی میتوانند دادههای حسگرها، دستگاههای اینترنت اشیا (IoT) و فناوری عملیاتی (OT) را آنالیز کنند تا با استفاده از آن، زمان نیاز به تعمیر و نگهداری و خرابی تجهیزات را قبل از وقوع پیشبینی کنند. تعمیر و نگهداری پیشگیرانه مبتنی بر هوش مصنوعی به جلوگیری از خرابی کمک میکند و به شما امکان میدهد تا با جلوتر بودن از مشکلات، قبل از اینکه آنها زنجیره تامین را تحت تاثیر قرار دهند، به آنها رسیدگی کنید.
چالش ها و خطرات هوش مصنوعی
سازمان ها در تلاش هستند تا از آخرین فناوری های هوش مصنوعی استفاده کنند و از مزایای فراوان آن بهره مند شوند. اقتباس و بکارگیری سریع تکنولوژی های هوش مصنوعی ضروری است؛ از طرفی دیگر پذیرش و حفظ جریان های کاری هوش مصنوعی با چالش ها و خطراتی نیز همراه است.
خطرات داده
سیستمهای هوش مصنوعی به مجموعههای دادهای متکی هستند که ممکن است در برابر مسمومیت دادهها، دستکاری دادهها، سوگیری دادهها یا حملات سایبری که میتواند منجر به نقض دادهها شود، آسیبپذیر باشد. سازمانها میتوانند این خطرات را با برخی تمهیدات کاهش دهند؛ برخی از این تمهیدات از این قرار هستند: محافظت از یکپارچگی دادهها و اجرای امنیت و در دسترس بودن در کل چرخه عمر هوش مصنوعی، از توسعه گرفته تا آموزش و استقرار و پس از استقرار.
خطرات مدل
عوامل تهدید می توانند مدل های هوش مصنوعی را با سرقت، مهندسی معکوس یا دستکاری غیرمجاز هدف قرار دهند. مهاجمان ممکن است یکپارچگی یک مدل را با دستکاری در اجزای اصلی آن که رفتار، دقت و عملکرد یک مدل را تعیین می کنند (از قبیل معماری، وزن یا پارامترهای آن) به خطر بیاندازند.
ریسک های عملیاتی
مانند همه تکنولوژیها، مدلها در معرض خطرات عملیاتی مانند رانش مدل (model drift)، سوگیری و خرابی در ساختار حاکمیت هستند. در صورت عدم رسیدگی، این خطرات می توانند منجر به خرابی سیستم و همچنین آسیب پذیری های امنیت سایبری شوند؛ این آسیب پذیری ها می توانند توسط عوامل تهدید مورد استفاده قرار گیرند.
هوش مصنوعی ضعیف در مقایسه با هوش مصنوعی قوی
به منظور زمینه سازی استفاده از هوش مصنوعی در سطوح مختلف پیشرفت، محققان انواع مختلفی از هوش مصنوعی را تعریف کرده اند که به سطح پیچیدگی آن اشاره دارد:
هوش مصنوعی ضعیف: هوش مصنوعی ضعیف یا باریک شامل سیستم های هوش مصنوعی می شود که برای انجام یک کار خاص یا مجموعه ای از وظایف طراحی شده اند. از مثالهای این نوع هوش می توان اپلیکیشن های دستیار صوتی هوشمند مانند الکسای آمازون، سیری اپل، ربات های چت رسانههای اجتماعی یا وسایل نقلیه خودران تسلا را بیان کرد.
هوش مصنوعی قوی: هوش مصنوعی قوی یا هوش عمومی مصنوعی (AGI)، به توانایی درک، یادگیری و به کارگیری دانش در طیف گسترده ای از وظایف در سطحی برابر یا فراتر از هوش انسانی اشاره دارد. این سطح از هوش مصنوعی در حال حاضر در حد تئوری است و هیچ سیستم هوش مصنوعی شناخته شده ای به این سطح از پیشرفت نرسیده است. محققان استدلال می کنند که حتی اگر AGI امکان پذیر باشد، نیازمند افزایش اساسی قدرت محاسباتی است. علیرغم پیشرفتهای اخیر در توسعه هوش مصنوعی، سیستمهای علمی تخیلی هوش مصنوعی خودآگاه همچنان در این حوزه باقی خواهند ماند.
تاریخچه هوش مصنوعی
ایده ماشینی که قادر به تفکر است ریشه در یونان باستان دارد. از زمان ظهور محاسبات الکترونیکی، موارد زیر رخدادها و نقاط عطف مهم در تکامل هوش مصنوعی هستند:
1950
مقاله ماشینها و هوش محاسباتی توسط آلن تورینگ منتشر شد؛ معروفیت تورینگ به شکستن کد ENIGMA آلمان در طول جنگ جهانی دوم است و از وی اغلب به عنوان پدر علوم کامپیوتری نیز یاد می شود. در این مقاله علاوه بر ارائه آزمون تورینگ این سوال نیز مطرح شد که آیا ماشین ها قادر به تفکر هستند؟
1956
جان مک کارتی در اولین کنفرانس هوش مصنوعی در کالج دارتموث، اصطلاح هوش مصنوعی را ابداع کرد و زبان Lisp توسط وی اختراع شد؛ در اواخر همان سال، آلن نیول، جی سی شاو و هربرت سایمون، اولین برنامه کامپیوتری هوش مصنوعی بنام Logic Theorist را ارائه کردند.
1967
فرانک روزنبلات Mark 1 Perceptron را به عنوان اولین کامپیوتر مبتنی بر یک شبکه عصبی که از طریق آزمون و خطا یاد می گرفت را ساخت. یک سال بعد، کتاب پرسپترونها توسط ماروین مینسکی و سیمور پیپرت منتشر شد.
1980
شبکه های عصبی که از یک الگوریتم پس انتشار برای آموزش خود استفاده می کنند، به طور گسترده در اپلیکیشن های هوش مصنوعی مورد استفاده قرار گرفتند.
1995
استوارت راسل و پیتر نورویگ کتاب هوش مصنوعی: رویکردی مدرن را منتشر کردند که در آن، به چهار هدف یا تعریف بالقوه هوش مصنوعی پرداخته شده است.
1997
دیپ بلو در یک مسابقه شطرنج، قهرمان شطرنج جهان، گری کاسپاروف را شکست داد.
2004
جان مک کارتی با انتشار مقاله ای با عنوان هوش مصنوعی چیست؟ تعریفی از هوش مصنوعی ارائه کرد که اغلب به آن استناد می شود.
2011
Watson تولید شرکت IBM، کن جنینگز و برد راتر را در بازی Jeopardy شکست داد. همزمان، علم داده به عنوان یک رشته محبوب ظهور می کند.
2015
ابر کامپیوتر مینوا از یک شبکه عصبی عمیق خاص به نام شبکه عصبی کانولوشنال برای شناسایی و دستهبندی تصاویر با دقت بالاتری نسبت به انسان معمولی استفاده کرد.
2022
افزایش مدلهای زبانی بزرگ (large language models) به اختصار LLM، مانند ChatGPT از شرکت OpenAI تغییر عظیمی در عملکرد هوش مصنوعی و پتانسیل آن برای افزایش ارزش سازمانی ایجاد کرد. با این شیوههای جدید هوش مصنوعی مولد، بر اساس مقادیر زیادی داده میتوان مدلهای یادگیری عمیق را از قبل آموزش داد.
2024
آخرین روندهای هوش مصنوعی به تداوم رنسانس هوش مصنوعی اشاره دارد. مدلهای چندوجهی میتوانند انواع مختلفی از دادهها را به عنوان ورودی دریافت کنند و تجربیات غنیتر و قویتری ارائه کنند. این مدلها قابلیتهای تشخیص تصویر computer vision و تشخیص گفتار NLP را با هم ترکیب میکنند.
سخن پایانی
در مطلب امروز هوش مصنوعی (artificial Intelligence) یا به اختصار AI بررسی شد و عنوان شد که هوش مصنوعی شاخه ای از تکنولوژی است که کامپیوترها و ماشینها را قادر میسازد تا یادگیری، درک، حل مسئله، تصمیمگیری، خلاقیت و استقلال انسان را شبیهسازی کنند. در گام بعد زیر مجموعه های این تکنولوژی یعنی یادگیری ماشین، یادگیری عمیق و هوش مصنوعی مولد مورد کنکاش قرار گرفت.
موارد استفاده و مزایا و چالش های فراروی هوش مصنوعی موضوعات دیگری بودند که در این مطلب به آنها اشاره شد و در نهایت با مرور تاریخچه این بخش از علوم کامپیوتری مقاله را به پایان رساندیم.
سوالات متداول
هوش مصنوعی به زبان ساده چیست؟
هوش مصنوعی (AI) به سیستمهای کامپیوتری اطلاق میشود که قادر به انجام وظایف پیچیدهای هستند که سابقا فقط توسط انسان قابل انجام بودند؛ استدلال، تصمیمگیری یا حل مشکلات نمونه هایی از این وظایف هستند.
هوش مصنوعی خوب است یا بد؟
ذاتاً نه می توان گفت که هوش مصنوعی خوب است و نه می توان آن را کلا بد دانست؛ ابزاری است که بسته به نحوه توسعه و کاربری، می توان آن را برای اهداف مفید و مضر استفاده کرد. برای تعامل با هوش مصنوعی باید بسیار محتاط و مسئولیت پذیر بود تا اطمینان حاصل شود که استفاده از آن به شیوه ای اخلاقی و شفاف انجام می شود.
امروزه از هوش مصنوعی چگونه استفاده می شود؟
از هوش مصنوعی به طور گسترده ای استفاده می شود، به عنوان مثال بر اساس جستجوها و خریدهای قبلی یا سایر رفتارهای آنلاین آنها می توان توصیه های شخصی به افراد ارائه کرد. هوش مصنوعی در تجارت نیز بسیار مهم است؛ بهینه سازی محصولات، برنامه ریزی موجودی، تدارکات و بسیاری موارد دیگر از جمله کارکردهای هوش مصنوعی هستند.
آیا هوش مصنوعی قادر خواهد بود جهان را تحت کنترل خود درآورد؟
اگر به داستان های علمی تخیلی اعتقاد دارید، پس معنای کلمه تخیلی را نمی دانید. پاسخ کوتاه به این ترس منفی است؛ هوش مصنوعی جهان را تسخیر نخواهد کرد، حداقل نه به شیوه ای که در فیلم ها به تصویر کشیده می شود.
یادگیری ماشین (Machine Learning) یکی از شاخههای پیشرفته و جذاب هوش مصنوعی است که توانایی سیستمهای کامپیوتری را در یادگیری و بهبود عملکردشان از طریق دادهها افزایش میدهد. با توجه به رشد روزافزون حجم دادهها در دنیای امروزی، یادگیری ماشین به ابزاری اساسی برای تحلیل و استخراج الگوها از این دادهها تبدیل شده است. از تجارت و پزشکی تا حمل و نقل و امنیت سایبری، کاربردهای یادگیری ماشین به طرز قابل توجهی در حال گسترش است و به سازمانها این امکان را میدهد تا تصمیمگیریهای بهتری داشته و کارایی خود را افزایش دهند. در این مقاله به بررسی مفهوم، کاربردها و انواع مختلف یادگیری ماشین میپردازیم، با ما همراه باشید.
یادگیری ماشین چیست؟
یادگیری ماشین (Machine learning) شاخهای از هوش مصنوعی است که تمرکز آن به ساختن سیستمهای کامپیوتری است که از دادهها یاد میگیرند. گستردگی تکنیک های یادگیری ماشین، اپلیکیشن های نرم افزاری را قادر می سازد تا عملکرد خود را در طول زمان بهبود بخشند.
الگوریتم های یادگیری ماشین برای یافتن روابط و الگوها در داده ها، آموزش داده شده اند. این الگوریتم ها می توانند با استفاده از داده های قبلی به عنوان ورودی اقدام به اموری نظیر پیش بینی، طبقه بندی اطلاعات، خوشه بندی داده ها، کاهش ابعاد و حتی تولید محتوای جدید کنند. ChatGPT محصول شرکت OpenAI و Claude and GitHub Copilot محصول شرکت Anthropic نمونههایی از یادگیری ماشین هستند که گاه از آن به عنوان هوش مصنوعی مولد نیز یاد میشود.
یادگیری ماشین در بسیاری از صنایع به صورت گسترده ای قابل اجرا است. به عنوان مثال، تجارت الکترونیک، رسانه های اجتماعی و سازمان های خبری از موتورهای توصیه استفاده می کنند تا بر اساس رفتار گذشته مشتری، برای او محتوای جدید پیشنهاد دهند.
در اتومبیل های خودران، الگوریتم های یادگیری ماشین و بینایی کامپیوتری (computer vision) نقش مهمی درمسیر یابی ایمن ایفا می کنند. در بخش پزشکی، یادگیری ماشین می تواند در تشخیص و پیشنهاد برنامه های درمانی کمک کند. سایر موارد رایج استفاده از یادگیری ماشین عبارت هستند از تشخیص کلاهبرداری، فیلترینگ اِسپم، شناسایی تهدید بدافزار، تعمیر و نگهداری پیشگیرانه و اتوماسیون فرآیندهای تجاری است.
یادگیری ماشین ابزاری قدرتمند برای حل مشکلات، بهبود عملیات کسب و کار و خودکار سازی وظایف است، ولی در عین حال پیچیده و نیازمند منابع فراوانی است و همچنین به تخصص عمیق و داده ها و زیرساخت های قابل توجهی نیاز دارد. برای انتخاب الگوریتم مناسب، باید درک قوی از ریاضیات و آمار را بکار بست. طراحی الگوریتم های یادگیری ماشین اغلب به مقادیر زیادی داده با کیفیت بالا نیاز دارد تا نتایج دقیقی تولید شود.
نتایج به نوبه خود، به ویژه آن دسته که از الگوریتم های پیچیده ای مانند شبکه های عمیق عصبی حاصل شده اند، می توانند دشوار باشد. از طرفی اجرا و تنظیم دقیق مدلهای یادگیری ماشین میتواند هزینه های زیادی را ایجاد کنند.
در حال حاضر بیشتر سازمانها در حال استفاده از یادگیری ماشین چه بهطور مستقیم و چه از طریق محصولات تولید شده با یادگیری ماشین هستند. بر اساس گزارش شرکت Rackspace Technology که در سال 2024 منتشر شد، انتظار میرود هزینههای هوش مصنوعی در سال جاری در مقایسه با سال 2023 بیش از دو برابر شود.
86 درصد از شرکتهای بررسی شده اعلام کردهاند که بکارگیری هوش مصنوعی برایشان سودمند بوده است. گزارش ها حاکی از این هستند که شرکت ها از این تکنولوژی برای افزایش تجربه مشتری (53%)، نوآوری در طراحی محصول (49%)، پشتیبانی از منابع انسانی (47%)، و چندین استفاده دیگر بهره برده اند.
اهمیت یادگیری ماشین
از زمان پیدایش آن در اواسط قرن بیستم، یادگیری ماشین نقش فزاینده مهمی در جامعه بشری ایفا کرده است. آموزش ماشینها برای یادگیری از دادهها و بهبود در طول زمان، سازمانها را قادر ساخته تا با خودکار سازی وظایف روتین، زمان فراغتی برای انسانها فراهم کنند تا کارهای خلاقانهتر و استراتژیکتری را انجام دهند.
یادگیری ماشین کاربردهای عملی گسترده و متنوعی دارد. در امور مالی، الگوریتمهای یادگیری ماشین به بانکها کمک میکنند تا با آنالیز آنی حجم عظیمی از دادهها، که از نظر سرعت و دقت غیر قابل مقایسه با انسانهاست، تراکنشهای جعلی را شناسایی کنند.
در حوزه درمان، یادگیری ماشین به پزشکان در تشخیص بیماریها بر اساس تصاویر پزشکی کمک میکند و برنامههای درمانی را به همراه مدلهای پیشبینیکننده نتایج بیماری اطلاعرسانی میکند. در حوزه خرده فروشی، بسیاری از شرکت ها از یادگیری ماشین استفاده می کنند تا تجربیات خرید افراد را تجسم کنند، اقلام مورد نیاز را توسط یادگیری ماشین پیش بینی کنند و زنجیره تامین را بهبود ببخشند.
یادگیری ماشین همچنین کارهای دستی که فراتر از توانایی انسان است را انجام می دهد؛ برای مثال، پردازش مقادیر عظیمی از داده هایی که روزانه توسط دستگاه های دیجیتال تولید می شود. توانایی استخراج الگوها و ایجاد بینش از مجموعه داده های گسترده، به یک تمایز رقابتی در زمینه هایی مانند بانکداری و اکتشافات علمی بدل شده است. بسیاری از شرکتهای پیشرو امروزی، از جمله متا، گوگل و اوبر، با ادغام یادگیری ماشین در عملیات خود تصمیمگیری ها را آگاه تر کرده اند و کارایی را بهبود بخشیده اند.
درک حجم روزافزون داده های تولید شده در جوامع مدرن، یادگیری ماشین را به یک ضرورت تبدیل است. از دادههای فراوانی که انسان ها ایجاد میکنند نیز میتوان برای آموزش بیشتر، تنظیم دقیق مدلهای یادگیری ماشین و تسریع در پیشرفتهای مرتبط با یادگیری ماشین استفاده کرد. این حلقه یادگیری مداوم، پیشرفتهترین سیستمهای هوش مصنوعی امروزی را با تاثیرات عمیق پشتیبانی می کند.
چشمانداز ماشینهایی که حجم وسیعی از دادهها را پردازش میکنند، درک انسان از هوش خود و نقشش در تفسیر و عمل بر اساس اطلاعات پیچیده را به چالش کشیده است و ملاحظات اخلاقی مهمی را در مورد تصمیمات اتخاذ شده توسط مدل های پیشرفته یادگیری ماشین برانگیخته است.
شفافیت و توضیح پذیری در آموزش یادگیری ماشین و تصمیم سازی در این باره، همچنین تأثیرات این مدل ها در اشتغال و ساختارهای اجتماعی، زمینه هایی برای نظارت و بحث مداوم در این حوزه هستند.
انواع مختلف یادگیری ماشین
طبقهبندی یادگیری ماشین کلاسیک اغلب بر اساس نحوه یادگیری الگوریتم در پیشبینی دقیقتر بود. چهار نوع اصلی یادگیری ماشین عبارتند از:
یادگیری تحت نظارت
یادگیری بدون نظارت
یادگیری نیمه نظارتی
یادگیری تقویتی
انتخاب نوع الگوریتم به ماهیت داده بستگی دارد. بسیاری از الگوریتم ها و تکنیک ها به یک نوع یادگیری ماشین محدود نمی شوند؛ بسته به موضوع و مجموعه دادهها، میتوانند با انواع مختلفی از یادگیری ماشین تطبیق داده شوند.
به عنوان مثال، الگوریتمهای یادگیری عمیق (deep learning) مانند شبکههای عصبی پیچشی (کانولوشنال) و تکراری (براساس مشکل خاص و در دسترس بودن داده)، در وظایف یادگیری تحت نظارت، بدون نظارت و تقویتی مورد استفاده قرار می گیرند.
مقایسه یادگیری ماشین وشبکه های عصبی یادگیری عمیق
یادگیری عمیق زیرشاخه ای از یادگیری ماشین است که بر مدل هایی با سطوح چندگانه شبکه های عصبی، معروف به شبکه های عصبی عمیق تمرکز دارد. این مدل ها می توانند به طور اتوماتیک ویژگی های سلسله مراتبی را از داده ها یاد گرفته و استخراج کنند تا آنها را برای اموری نظیر تشخیص تصویر و گفتار استفاده کنند.
یادگیری تحت نظارت چگونه کار می کند؟
یادگیری تحت نظارت الگوریتمهایی با برچسب دادههای آموزشی تامین میکند و همچنین وظیفه تعریف اینکه کدام متغیرها برای همبستگی باید توسط الگوریتم ارزیابی شوند، نیز بر عهده این نوع یادگیری است. هم ورودی و هم خروجی الگوریتم معین است. در ابتدا، اکثر الگوریتمهای یادگیری ماشین از یادگیری تحت نظارت استفاده میکردند، اما رفته رفته رویکردهای بدون نظارت محبوبیت یافتند.
الگوریتم های یادگیری تحت نظارت برای وظایف متعددی از جمله موارد زیر استفاده می شود:
طبقه بندی باینری: این الگوریتم داده ها را به دو دسته تقسیم می کند.
طبقه بندی چندگانه: در این الگوریتم انتخاب از بین بیش از دو دسته است.
یادگیری ماشین مدلسازی گروهی: الگوریتم مدلسازی گروهی پیشبینیهای چند مدل یادگیری ماشین را برای ایجاد یک پیشبینی دقیقتر ترکیب میکند.
مدلسازی رگرسیون: این الگوریتم مقادیر پیوسته را بر اساس روابط درون داده ها پیش بینی می کند.
الگوریتم رگرسیون دارای پنج نوع متفاوت است و استفاده ایده آل آنها متفاوت است. برای مثال، رگرسیون خطی در پیشبینی خروجیهای پیوسته برتری دارد، در حالی که برتری رگرسیون سری در پیشبینی مقادیر آینده است. انواع الگوریتم های رگرسیون: خطی، لجستیکی، چند جمله ای، سری زمانی، بردار پشتیبانی.
یادگیری بدون نظارت چگونه کار می کند؟
یادگیری بدون نظارت نیازمند داده های برچسب دار نیست؛ در عوض، این الگوریتمها دادههای بدون برچسب را برای شناسایی الگوها و گروهبندی نقاط داده به زیرمجموعهها، آنالیز میکنند. انواع یادگیری عمیق (deep learning)، از جمله شبکه های عصبی از این نوع الگوریتم هستند.
یادگیری بدون نظارت برای امور مختلف مورد استفاده است، از جمله:
تقسیم مجموعه داده ها به گروه ها بر اساس شباهت با استفاده از الگوریتم های خوشه بندی.
شناسایی نقاط داده غیرعادی در یک مجموعه از داده با استفاده از الگوریتم های تشخیص ناهنجاری.
کشف مجموعه ای از آیتم ها در یک مجموعه داده که اغلب با هم اتفاق می افتد با استفاده از استخراج قواعد وابستگی.
کاهش تعداد متغیرها در یک مجموعه داده با استفاده از تکنیک های کاهش ابعاد.
یادگیری نیمه نظارتی چگونه کار می کند؟
یادگیری نیمه نظارتی تنها با مقدار کمی از داده های آموزشی برچسب گذاری شده، الگوریتمی ارائه می کند. با استفاده از این دادهها، الگوریتم ابعاد مجموعه دادهها را میآموزد، سپس میتواند آنها را روی دادههای جدید و بدون برچسب اعمال کند.
با این حال، توجه داشته باشید که ارائه دادههای آموزشی بسیار کم میتواند منجر به بیش برازش (overfitting) شود؛ در مدل بیش برازش بهجای یادگیری واقعی الگوهای اساسی، دادههای آموزشی فقط حفظ می شوند.
اگرچه عملکرد الگوریتمها معمولاً وقتی روی مجموعه دادههای برچسبدار آموزش میدهند بهتر است، با این حال برچسبگذاری زمانبر و پرهزینه است. یادگیری نیمه نظارتی، عناصر یادگیری تحت نظارت و یادگیری بدون نظارت را ترکیب می کند و تعادلی بین عملکرد برتر اولی و کارایی دومی ایجاد می کند.
از یادگیری نیمه نظارتی در زمینه های زیر می توان استفاده کرد:
ترجمه ماشینی. الگوریتم ها می توانند ترجمه یک زبان را بر اساس کمتر از یک لغتنامه کامل یاد بگیرند.
کشف کلاهبرداری. الگوریتم ها می توانند شناسایی موارد تقلب را تنها با استفاده از چند مثال مثبت یاد بگیرند.
برچسب گذاری داده ها. الگوریتم هایی که با استفاده از مجموعه کوچکی از داده ها آموزش داده شده اند، می توانند اعمال خودکار برچسب های داده به مجموعه های بزرگتر را یاد بگیرند.
یادگیری تقویتی چگونه کار می کند؟
یادگیری تقویتی یعنی با یک هدف مشخص یک الگوریتم برنامه ریزی شود و مجموعه ای از قوانین برای دستیابی به آن هدف تدوین شوند. این الگوریتم با انجام اقداماتی که آن را به هدف خود نزدیک می کند، به دنبال دریافت پاداش های مثبت است و از مجازات شدن بخاطر انجام اقداماتی که آن را از هدفش دورتر می کند، اجتناب می کند.
یادگیری تقویتی اغلب برای کارهایی از جمله موارد زیر استفاده می شود:
کمک به ربات ها در یادگیری انجام وظایف در دنیای فیزیکی
آموزش بازی های ویدیویی به ربات ها
کمک به شرکت ها برای برنامه ریزی تخصیص منابع
نحوه انتخاب و ساخت مدل یادگیری ماشین مناسب
توسعه مدل یادگیری ماشین مناسب برای حل یک مشکل نیازمند استقامت، آزمایش و خلاقیت است. اگرچه این فرآیند می تواند پیچیده باشد، ولی می توان آن را بصورت یک برنامه هفت مرحله ای برای ساخت یک مدل یادگیری ماشین خلاصه کرد.
درک مشکل کسب و کار و تعریف معیارهای موفقیت: اطلاعات گروه از مشکل شرکت و اهداف پروژه باید تبدیل به یک تعریف مناسب از مشکل یادگیری ماشین شود؛ همچنین مواردی زیر باید در نظر گرفته شوند: اینکه چرا پروژه به یادگیری ماشین نیازمند است، بهترین نوع الگوریتم برای مشکل چیست، الزامات شفافیت و کاهش تعصب چه مواردی هستند و در نهایت ورودی ها و خروجی های مورد انتظار چه هستند.
درک و شناسایی نیازهای داده: باید تعیین شود چه داده هایی برای ساخت مدل لازم است و آمادگی آن برای جذب مدل ارزیابی شود. باید در نظر گرفت که چه مقدار داده مورد نیاز است، چگونه داده به مجموعه های آزمایشی و آموزشی تقسیم خواهد شد و آیا می توان از یک مدل یادگیری ماشین از پیش آموزش دیده استفاده کرد.
جمع آوری و آماده سازی داده برای آموزش مدل: داده ها باید پاک شده و برچسب گذاری شوند، این کار یادگیری ماشین شامل جایگزینی داده های نادرست یا از دست رفته، کاهش نویز و رفع ابهام می شود. این مرحله همچنین بسته به مجموعه داده ها می تواند شامل تقویت و افزایش داده ها و ناشناس سازی داده های شخصی نیز باشد. در نهایت، داده ها باید به مجموعه های آموزشی، آزمایشی و اعتبار سنجی تقسیم شوند.
تعیین ویژگی های مدل و آموزش آن: باید با انتخاب الگوریتم ها و تکنیک های مناسب، از جمله تنظیم فرا پارامترها، شروع کرد. در مرحله بعد، به مدل آموزش داده و اعتبارسنجی شود و سپس در صورت نیاز با تنظیم فرا پارامترها و وزن ها بهینه سازی انجام گیرد.
بسته به مشکل شرکت، الگوریتمها ممکن است شامل قابلیتهای درک زبان طبیعی، مانند شبکههای عصبی تکراری یا انتقال دهنده های وظایف پردازش زبان طبیعی (NLP) و یا الگوریتمهای تقویتی برای بهینهسازی مدلهای درخت تصمیم گیری باشند.
ارزیابی عملکرد مدل و ایجاد معیارها. باید محاسبات ماتریس در هم ریختگی انجام شود، معیارهای KPI و یادگیری ماشین کسب و کار تعیین شود، کیفیت مدل اندازه گیری شود و معین شود که آیا مدل با اهداف شرکت مطابقت دارد یا خیر.
استقرار مدل و نظارت بر عملکرد آن در تولید. این بخش از فرآیند، که به عنوان عملیاتی سازی مدل شناخته می شود، معمولاً به طور مشترک توسط دانشمندان داده و مهندسان یادگیری ماشین انجام می شود. در این بخش عملکرد مدل باید به طور مداوم اندازه گیری شود، معیارهایی برای تکرار مدل های آینده ایجاد شود و در نهایت برای بهبود عملکرد کلی، این موارد تکرار شوند. محیط های استقرار می تواند فضای ابری، لبه یا در محل باشد.
اصلاح و تنظیم مداوم مدل در تولید. حتی پس از تولید مدل یادگیری ماشین و نظارت مستمر، کار هنوز ادامه دارد. تغییرات در نیازهای کسب و کار، قابلیتهای تکنولوژی و دادههای دنیای واقعی میتوانند خواستهها و الزامات جدیدی را ایجاد کند.
اپلیکیشن های یادگیری ماشین برای شرکت ها
یادگیری ماشین به یک نرم افزار ضروری برای کسب و کارها تبدیل شده است. در زیر چند نمونه از نحوه استفاده اپلیکیشن های تجاری مختلف از یادگیری ماشین آورده شده است:
هوش تجاری: هوش تجاری( Business intelligence) یا BI و نرمافزار تحلیلی پیشبینیکننده از الگوریتمهای یادگیری ماشین، از جمله رگرسیون خطی و رگرسیون لجستیک استفاده می کنند تا نقاط داده، الگوها و ناهنجاریهای مهم را در مجموعههای داده بزرگ شناسایی کنند. این بینش به کسب و کارها کمک می کند تا تصمیمات مبتنی-بر-داده اتخاذ کنند، روندها را پیش بینی کرده و عملکرد را بهینه سازی کنند.
پیشرفت در هوش مصنوعی مولد (generative AI) همچنین امکان ایجاد گزارش های دقیق و داشبوردهایی را فراهم آورده است که داده های پیچیده را در قالب هایی که به راحتی قابل درک هستند خلاصه می کند.
مدیریت ارتباط با مشتری: کاربردهای کلیدی یادگیری ماشین در CRM (مدیریت ارتباط با مشتری) شامل آنالیز دادههای مشتری برای تقسیمبندی مشتریان، پیشبینی رفتارهایی مانند انحراف، ارائه توصیههای شخصی، تنظیم قیمت، بهینهسازی کمپینهای ایمیل، ارائه پشتیبانی از چتبات و کشف تقلب می شود.
هوش مصنوعی مولد همچنین میتواند محتوای بازاریابی هوشمند ایجاد کند، پاسخ دهی را در خدمات مشتری خودکار کند و بینشی بر اساس بازخورد مشتری ایجاد کند.
امنیت و انطباق: ماشینهای بردار پشتیبان میتوانند با یافتن بهترین خط یا مرز برای تقسیم دادهها به گروههای مختلف، انحرافات در رفتار نسبت به یک خط مبنای معمولی را تشخیص دهند؛ تشخیص انحراف برای شناسایی تهدیدات سایبری بالقوه حیاتی است. شبکههای متخاصم مولد میتوانند نمونههای بدافزار متخاصم ایجاد کنند تا در آموزش مدلهای یادگیری ماشین به تیمهای امنیتی کمک کنند.
سیستم های اطلاعات منابع انسانی: مدلهای یادگیری ماشین استخدام را با فیلتر کردن اپلیکیشن ها و شناسایی بهترین نامزدها برای یک موقعیت ساده میکنند. آنها همچنین می توانند گردش کار کارکنان را پیش بینی کنند، مسیرهای توسعه حرفه ای را پیشنهاد کنند و زمان بندی مصاحبه را خودکار کنند. هوش مصنوعی مولد می تواند در ایجاد شرح وظایف شغلی و تولید مواد آموزشی شخصی کمک کند.
مدیریت زنجیره تامین: یادگیری ماشین می تواند سطوح موجودی را بهینه کند، لجستیک را ساده کند، انتخاب تامین کننده را بهبود بخشد و به صورت فعالانه ای به اختلالات زنجیره تامین رسیدگی کند. آنالیز پیشبینیکننده میتواند تقاضا را با دقت بیشتری پیشبینی کند و شبیهسازهای مبتنی بر هوش مصنوعی میتوانند سناریوهای مختلفی را برای بهبود انعطافپذیری مدلسازی کنند.
پردازش زبان طبیعی: اپلیکیشن های (Natural language processing یا پردازش زبان طبیعی) NLP شامل آنالیز احساسات، ترجمه زبان و خلاصه سازی متن و غیره می شود. پیشرفت های هوش مصنوعی مولد، مانند GPT-4 محصول شرکت OpenAIیادگیری ماشین و Gemini محصول شرکت Google، این قابلیت ها را به طور قابل توجهی افزایش داده است.
مدلهای NLP مولد میتوانند متونی شبیه متون انسانی تولید کنند، دستیارهای مجازی را بهبود بخشند و اپلیکیشن های پیچیدهتر مبتنی بر زبان، از جمله ایجاد محتوا و خلاصهسازی اسناد را فعال کنند.
نمونه های یادگیری ماشین در صنعت
اقتباس سازمانی تکنیک های یادگیری ماشین در سراسر صنایع، در حال متحول سازی فرآیندهای کسب و کار هستند. چند نمونه را بررسی می کنیم:
خدمات مالی: شرکت Capital One ازیادگیری ماشین برای تقویت تشخیص کلاهبرداری، ارائه تجربیات شخصی مشتری و بهبود برنامه ریزی تجاری استفاده می کند. این شرکت از متدولوژی یادگیری ماشین Ops برای استقرار اپلیکیشن های یادگیری ماشین در مقیاس مورد نیاز بهره می برد.
داروسازی: سازندگان دارو از یادگیری ماشین برای کشف دارو، آزمایشات بالینی و تولید دارو استفاده می کنند. به عنوان مثال، شرکت داروسازی اِلی لیلی مدلهای هوش مصنوعی و یادگیری ماشین را برای یافتن بهترین سایتها برای آزمایشهای بالینی و افزایش تنوع شرکتکنندگان ایجاد کرده است. به گفته این شرکت، مدلها توانسته اند جدول زمانی آزمایشهای بالینی را به شدت کاهش دهند.
بیمه: برنامه معروف شرکت بیمه ای پراگرسیو بنام Snapshot از الگوریتم های یادگیری ماشین برای آنالیز داده های رانندگی استفاده می کند و نرخ های بیمه پایین تری را به رانندگان ایمن ارائه می دهد. دیگر کاربرد مفید یادگیری ماشین در صنعت بیمه شامل رسیدگی به خسارت است.
خرده فروشی: شرکت والمارت از ابزار هوش مصنوعی مولد My Assistant برای کمک به حدود 50000 کارمند پردیس خود در تولید محتوا، خلاصه کردن اسناد بزرگ و همچنین درخواست بازخورد کارکنان استفاده می کند.
مزایا و معایب یادگیری ماشین چیست؟
اگر یادگیری ماشین به طور مؤثری به کار گرفته شود، ارائه کننده مزیتی رقابتی برای مشاغل خواهد بود؛ چراکه روندها را شناسایی می کند و نتایج را با دقت بالاتری نسبت به آمارهای متعارف یا هوش انسانی پیش بینی می کند. یادگیری ماشین به چندین روش می تواند برای مشاغل مفید باشد:
آنالیز داده های قبلی برای حفظ مشتریان
راه اندازی سیستم های توصیه کننده برای افزایش درآمد
بهبود برنامه ریزی و پیش بینی
ارزیابی الگوهای کشف کلاهبرداری
افزایش کارایی و کاهش هزینه ها
اما یادگیری ماشین برخی چالش های تجاری را نیز به همراه دارد. مهمترین مسئله احتمالا قیمت بالای یادگیری ماشین باشد. یادگیری ماشین نیازمند نرمافزارها، سختافزارها و زیرساختهای مدیریتی داده پرهزینه ای است و پروژههای یادگیری ماشین معمولاً توسط دانشمندان و مهندسانی پیش برده می شوند که حقوق های بالایی دریافت می کنند.
موضوع مهم دیگر جهت گیری های یادگیری ماشین است. الگوریتم های آموزش داده شده بر روی مجموعه داده هایی که جمعیت های خاصی را نادیده می گیرند یا حاوی خطاهایی هستند، می توانند به طراحی مدل های نادرست منجر شوند.
مدل ها گاه با شکست مواجه می شوند و گاها در بدترین حالت، نتایج تبعیض آمیزی تولید می کنند. اگر فرآیندهای اصلی سازمانی بر اساس مدلهای مغرضانه مستقر شوند، این موضوع منجر به آسیب قانونی و اعتباری برای کسبوکارها خواهد شد.
اهمیت یادگیری ماشین قابل تفسیر توسط انسان
توضیح عملکرد داخلی یک مدل خاص یادگیری ماشین می تواند چالش برانگیز باشد، به خصوص زمانی که مدل پیچیده باشد. با تکامل یادگیری ماشین، اهمیت مدلهای شفاف و قابل توضیح به ویژه در صنایعی مانند بانکداری و صنعت بیمه نیز افزایش مییابد.
به دلیل پیشرفت های سریع و اقتباس تکنیکهای پیچیده یادگیری ماشین مانند هوش مصنوعی مولد، توسعه مدلهای یادگیری ماشین با نتایج قابل درک و توضیح برای انسان به یک اولویت تبدیل شده است. محققان آزمایشگاههای هوش مصنوعی مانند آنتروپیک با استفاده از تکنیکهای تفسیرپذیری و توضیح پذیری، به پیشرفت هایی در زمینه درک نحوه عملکرد مدلهای هوش مصنوعی مولد دست یافته اند.
هوش مصنوعی قابل تفسیر و هوش مصنوعی قابل توضیح
تمرکز تفسیرپذیری به درک عمیق عملکردهای درونی یک مدل یادگیری ماشین است، در حالی که توضیح پذیری شامل توصیف تصمیم گیری مدل به روشی قابل درک است. معمولاً سر و کار دانشمندان حوزه داده و سایر متخصصان یادگیری ماشین با تکنیکهای یادگیری ماشین تفسیر پذیر است، در حالیکه از توضیح پذیری اغلب برای درک مدلهای یادگیری ماشین برای کمک به افراد غیرمتخصص استفاده می شود. برای مثال یک مدل به اصطلاح جعبه سیاه حتی اگر قابل تفسیر نباشد، احتمالا قابل توضیح خواهد بود.
محققان میتوانند ورودیهای مختلف را آزمایش کنند و تغییرات در خروجیها را با استفاده از روشهایی مانند SHAP (مخفف توضیحات افزودنی Shapley) مشاهده کنند تا بدانند تاثیر کدام عوامل بر خروجی بیشتر است. به این ترتیب، محققان میتوانند به تصویر واضحی از نحوه تصمیمگیری مدل (توضیح پذیری) برسند، حتی اگر مکانیک شبکه عصبی پیچیده داخل (تفسیر پذیری) را به طور کامل درک نکنند.
هدف تکنیکهای یادگیری ماشین قابل تفسیر شفاف سازی فرآیند تصمیمگیری مدل است. حال چند نمونه بیان می شود:
درخت های تصمیم گیری که نمایشی بصری از مسیرهای تصمیم گیری را ارائه می دهند.
رگرسیون خطی که پیشبینیهای مبتنی بر مجموع وزنی ویژگیهای ورودی را توضیح میدهد.
شبکه های Bayesian که وابستگی بین متغیرها را به روشی ساختار یافته و قابل تفسیر نشان می دهند.
از تکنیکهای هوش مصنوعی قابل توضیح (XAI) زمانی استفاده میشوند که قصد داشته باشیم خروجی مدلهای پیچیدهتر یادگیری ماشین را برای ناظران انسانی قابل درکتر کنیم. مثالها این مورد عبارت اند از:
LIME که رفتار مدل را به صورت محلی با مدلهای سادهتر برای توضیح پیشبینیهای فردی شبیه سازی میکند.
مقادیر SHAP، که وظیفه اختصاص امتیاز های اهمیت به ویژگی ها را دارد تا روشن کند که چگونه در تصمیمگیری مدل نقش دارند.
الزامات شفافیت می تواند در انتخاب یک مدل یادگیری ماشین دخیل باشد
در برخی از صنایع، دانشمندان داده باید از مدلهای ساده یادگیری ماشین استفاده کنند، چرا که برای کسبوکارها توضیح نحوه تصمیم گیری اهمیت دارد. نیاز به شفافیت اغلب منجر به برقراری نوعی تعادل بین سادگی و دقت می شود. اگرچه مدلهای پیچیده میتوانند پیشبینیهای بسیار دقیقی تولید کنند، ولی توضیح خروجیهای آنها برای یک فرد عادی (یا حتی یک متخصص) میتواند دشوار باشد.
مدلهای سادهتر و قابل تفسیرتر اغلب در صنایعی که دارای مقررات سفت و سختی هستند ترجیح داده میشوند؛ چرا که در این صنایع تصمیمها باید قابل توجیه و حسابرسی باشند. پیشرفتها در تفسیر پذیری و تکنیکهای هوش مصنوعی قابل توضیح (XAI)، استقرار مدلهای پیچیده را با حفظ شفافیت لازم برای انطباق و اعتماد، به طور فزایندهای امکانپذیر میسازد.
تیمهای یادگیری ماشین، نقشها و گردش کار
آغاز ساخت یک تیم یادگیری ماشین با تعریف اهداف و محدوده پروژه است. سوالات اساسی مطرح در این باره: تیم یادگیری ماشین چه مشکلات تجاری را باید حل کند؟ اهداف تیم چیست؟ برای ارزیابی عملکرد چه معیارهایی استفاده خواهد شد؟
پاسخ به این سوالات بخش اساسی در برنامه ریزی برای یک پروژه یادگیری ماشین است و به سازمان کمک خواهد کرد تا تمرکز پروژه (به عنوان مثال، تحقیق، توسعه محصول، آنالیز داده) و انواع تخصص های یادگیری ماشین مورد نیاز (به عنوان مثال، بینایی کامپیوتر، NLP، مدل سازی پیش بینی) را درک کند.
در مرحله بعد، بر اساس این ملاحظات و محدودیت های بودجه، سازمان ها باید تصمیم بگیرند که چه نقش های شغلی برای تیم یادگیری ماشین مورد نیاز است. بودجه پروژه نه تنها باید شامل هزینه های استاندارد منابع انسانی (مانند حقوق، مزایا و جذب نیروی کار جدید) باشد، بلکه ابزارهای یادگیری ماشین، زیرساخت ها و آموزش را نیز باید در بر بگیرد.
در حالی که ترکیب خاص یک تیم یادگیری ماشین متفاوت خواهد بود، اکثر تیمهای یادگیری ماشین سازمانی ترکیبی از متخصصان فنی و تجاری را شامل خواهد شد و هر کدام در حوزهای از تخصص به پروژه کمک خواهند کرد.
دانشمندان حوزه داده بر استخراج بینش از دادهها تمرکز میکنند، در حالی که مهندسان یادگیری ماشین مدلهای یادگیری ماشین را تهیه و مستقر می کنند، اما این دو نقش در مهارتها، پیشزمینه و مسئولیتهای شغلی همپوشانی هایی را دارند. هر دو گروه با پایتون شامل کتابخانه ها نظیر پانداها آشنا هستند، دارای دانش آماری، یادگیری ماشین و علوم کامپیوتری هستند و مهارتهای ارتباطی و همکاری را کسب کرده اند.
نقش های تیم یادگیری ماشین
یک تیم یادگیری ماشین معمولاً شامل برخی از نقشهای غیر یادگیری ماشین نیز است؛ مانند متخصصان دامنه که به تفسیر دادهها و اطمینان از ارتباط آنها با حوزه پروژه کمک میکنند؛ مدیران پروژه که بر چرخه عمر پروژه یادگیری ماشین نظارت دارند؛ مدیران محصول که مسئول برنامهریزی توسعه اپلیکیشن ها و نرمافزارهای یادگیری ماشین هستند و مهندسان نرم افزاری که این اپلیکیشن ها را می سازند.
علاوه بر این موارد، چندین نقش دیگر نیز برای یک تیم یادگیری ماشین ضروری هستند:
دانشمندان حوزه داده: دانشمندان این حوزه آزمایشهایی را طراحی میکنند و مدلهایی را برای پیشبینی نتایج و شناسایی الگوها ایجاد می کنند. آنها مجموعه دادهها را جمعآوری و آنالیز میکنند، دادهها را مرتب و پیش پردازش میکنند، معماریهای مدل را طراحی کرده و نتایج مدل را تفسیر میکنند و نهایتا رهبران کسبوکار و ذینفعان را در جریان امور قرار می دهند.
دانشمندان داده نیازمند تخصص در آمار، برنامه نویسی کامپیوتر و یادگیری ماشین هستند؛ از جمله زبان های محبوب یادگیری ماشین Python و یادگیری ماشین R و چارچوب هایی مانند یادگیری ماشین PyTorch و TensorFlowهستند.
مهندس داده: مهندسان داده مسئول زیرساخت های پشتیبانی از پروژه های یادگیری ماشین هستند تا اطمینان حاصل شود که داده ها به روشی قابل دسترس جمع آوری، پردازش و ذخیره می شوند. آنها خطوط لوله داده را طراحی، ساخت و نگهداری می کنند.
سیستم های پردازش داده در مقیاس بزرگ مدیریت می کنند و فرایندهای یکپارچه سازی داده را ایجاد و بهینه می سازند. آنها نیازمند تخصص در مدیریت پایگاه داده، انبارداری داده ها، برنامه نویسی زبان هایی مانند SQL یادگیری ماشین و Scala و تکنولوژی های داده های کلان مانند Hadoop یادگیری ماشین و Apache Spark هستند.
مهندس یادگیری ماشین: مهندسان یادگیری ماشین که به عنوان مهندسان یادگیری ماشین Ops نیز شناخته می شوند، با استفاده از خطوط لوله یادگیری ماشین که توسط مهندسان داده نگهداری می شوند، مدل های توسعه یافته توسط دانشمندان داده را به محیط های تولید انتقال می دهند.
آنها الگوریتم ها را برای اجرا بهینه می کنند؛ مدل های یادگیری ماشین را مستقر و نظارت می کنند؛ زیرساخت یادگیری ماشین را حفظ و مقیاس می کنند و چرخه عمر یادگیری ماشین را از طریق شیوه هایی مانند CI/CD و نسخه سازی داده ها خودکار می کنند. علاوه بر دانش یادگیری ماشین و هوش مصنوعی، مهندسان این حوزه معمولاً نیازمند تخصص در مهندسی نرم افزار، معماری داده و محاسبات ابری هستند.
مراحل ایجاد گردش کار یادگیری ماشین
زمانیکه که تیم یادگیری ماشین تشکیل شد، اجرا آرام و بی نقص اهمیت پیدا می کند. باید اطمینان حاصل شود که اعضای تیم به راحتی بتوانند دانش و منابع را به اشتراک بگذارند تا گردش کار مستمر باشد و بهترین شیوه ها اتخاذ شوند. به عنوان مثال، ابزارهای همکاری، کنترل نسخه و مدیریت پروژه، مانند Git و Jira باید پیاده سازی شوند.
مستندسازی شفاف و کامل برای اشکال زدایی، انتقال دانش و قابلیت نگهداری از اهمیت بالایی برخوردار است. در پروژههای یادگیری ماشین، این بخش شامل مستندسازی مجموعههای داده، اجرای مدل و کد با توضیحات مفصل منابع داده، مراحل پیشپردازش، معماریهای مدل، فرا پارامترها و نتایج آزمایش می شود.
یک روش متداول برای مدیریت پروژههای یادگیری ماشین، یادگیری ماشین Ops (عملیات یادگیری ماشین/ machine learning operations) است. یادگیری ماشین Ops مجموعهای از شیوهها برای استقرار، نظارت و نگهداری مدلهای یادگیری ماشین در تولید است.
از DevOps الهام گرفته شده است، اما تفاوت های ظریفی را که یادگیری ماشین را از مهندسی نرم افزار متمایز می کند را توضیح می دهد. همانطور که DevOps همکاری بین توسعه دهندگان نرم افزار و عملیات IT را بهبود میبخشد، یادگیری ماشین Ops نیز دانشمندان داده و مهندسان یادگیری ماشین را با تیم های توسعه و عملیات مرتبط می سازد.
سازمانها با اقتباس یادگیری ماشین Os ثبات، تکرارپذیری و همکاری در گردشهای کاری یادگیری ماشین را بهبود می بخشند. این شامل ردیابی آزمایشها، مدیریت نسخههای مدل و نگهداری گزارشهای دقیق دادهها و تغییرات مدل است. نگهداری سوابق نسخههای مدل، منابع داده و تنظیمات پارامتر تضمین میکند که تیمهای پروژه یادگیری ماشین به راحتی بتوانند تغییرات را ردیابی کنند و متوجه نحوه تأثیر متغیرهای مختلف بر عملکرد مدل شوند.
به طور مشابه، گردش کار استاندارد و اتوماسیون وظایف تکراری، زمان و انرژی مورد نیاز برای انتقال مدلها از توسعه به تولید را کاهش میدهد و این شامل خودکارسازی آموزش، آزمایش و استقرار مدل می شود. پس از استقرار، با نظارت مستمر و ثبت گزارش اطمینان حاصل خواهد شد که مدل ها همیشه با آخرین داده ها به روز میشوند و به صورت بهینه ای عمل خواهند کرد. انتظار می رود ارزش بازار جهانی هوش مصنوعی تا سال 2030 به حدود 2 تریلیون دلار برسد و نیاز به متخصصان ماهر هوش مصنوعی در حال افزایش باشد.
ابزارها و پلتفرم های یادگیری ماشین
توسعه یادگیری ماشین به طیف وسیعی از پلتفرم ها، چارچوب های نرم افزاری، کتابخانه های کد و زبان های برنامه نویسی متکی است. در این قسمت از مقاله یک مروری کلی از دسته های مختلف خواهیم داشت و برخی از ابزارهای برتر هر دسته را بررسی خواهیم کرد.
پلتفرم ها
پلتفرم های یادگیری ماشین محیط های یکپارچه ای هستند که ابزارها و زیرساخت هایی را برای پشتیبانی از چرخه عمر مدل یادگیری ماشین فراهم می کنند. عملکردهای کلیدی شامل این موارد هستند: مدیریت داده، توسعه مدل، آموزش، اعتبار سنجی و استقرار و همچنین نظارت و مدیریت پس از استقرار.
بسیاری از پلتفرمها همچنین دارای ویژگیهایی برای بهبود همکاری، انطباق و امنیت، و اجزای یادگیری ماشین خودکار (Auto یادگیری ماشین) هستند که وظایفی نظیر انتخاب مدل و پارامترسازی را خودکار میکنند.
هر کدام از 3 ارائهدهنده اصلی ابر (Google Vertex AI، Amazon SageMaker و Microsoft Azure ML) یک پلتفرم یادگیری ماشین ارائه میدهند که برای ادغام با اکوسیستم ابری خود طراحی شده اند. این محیط های یکپارچه، ابزارهایی را برای توسعه مدل، آموزش و استقرار، قابلیت های یادگیری ماشین خودکار و یادگیری ماشین Ops و پشتیبانی از چارچوب های محبوب مانند TensorFlow و PyTorch ارائه می دهند.
اغلب انتخاب به پلتفرمی ختم می شود که با محیط IT موجود یک سازمان ادغام شود. علاوه بر پیشنهادات ارائه دهندگان ابر، چندین جایگزین شخص ثالث و متن باز نیز وجود دارد. موارد زیر برخی دیگر از پلتفرم های محبوب یادگیری ماشین هستند: IBM Watson Studio، Databricks، Snowflake، DataRobot.
چارچوب ها و کتابخانه ها
چارچوبها و کتابخانههای یادگیری ماشین بلوکهای ساختمانی را برای توسعه مدل فراهم میکنند: مجموعهای از کارکردها و الگوریتمهایی که مهندسان یادگیری ماشین میتوانند از آن ها برای طراحی، آموزش و استقرار مدلهای یادگیری ماشین سریع تر و کارآمدتر استفاده کنند.
در دنیای واقعی، اصطلاحات چارچوب و کتابخانه اغلب به جای یکدیگر استفاده می شوند. اما به بیان دقیق تر، یک چارچوب عبارت است از یک محیط جامع با ابزارها و منابع سطح بالا برای ساخت و مدیریت اپلیکیشن های یادگیری ماشین؛ در حالی که یک کتابخانه مجموعه ای از کدهای قابل استفاده مجدد برای وظایف خاص یادگیری ماشین است. از رایج ترین چارچوب ها و کتابخانه های یادگیری ماشین می توان این موارد را نام برد: TensorFlow، PyTorch، Keras، Scikit-learn، OpenCV و NLTK.
زبان های برنامه نویسی
تقریباً همه زبان های برنامه نویسی را می توان برای یادگیری ماشین استفاده کرد. اما در عمل، اکثر برنامه نویسان زبانی را برای پروژه یادگیری ماشین انتخاب می کنند که ملاحظاتی نظیر در دسترس بودن کتابخانه های کد متمرکز برای یادگیری ماشین، پشتیبانی و تطبیق پذیری را دارا باشند.
بیشتر اوقات پایتون، پرکاربردترین زبان در یادگیری ماشین است؛ این زبان ساده و خوانا است در نتیجه برای تازه کاران کدنویسی یا توسعه دهندگان آشنا با دیگر زبان های کدنویسی مناسب خواهد بود. پایتون همچنین دارای طیف گسترده ای از علوم داده و کتابخانه ها و چارچوب های یادگیری ماشین، از جمله TensorFlow، PyTorch، Keras، scikit-learn، پانداها و NumPy است. سایر زبان های مورد استفاده در یادگیری ماشین این موارد هستند: R، Julia، C++، Scala و Java.
آینده یادگیری ماشین
با تحقیقات گسترده ای که از جانب شرکتها، دانشگاهها و دولتها در سراسر جهان انجام می شود، یادگیری ماشین به سرعت در حال تکامل است. پیشرفتهای حوزه هوش مصنوعی و یادگیری ماشین مکرر در حال وقوع است، و در نتیجه می توان گفت که شیوههای پذیرفتهشده تقریباً به محض ایجاد منسوخ می شوند. یکی از قطعیتها در مورد آینده یادگیری ماشین، ادامه یافتن نقش اصلی آن در قرن بیست و یکم است که نحوه انجام امور و زندگی ما را تحت تاثیر قرار خواهد داد.
چندین روند در حال ظهور، آینده یادگیری ماشین را شکل می دهند: NLP، بینش کامپیوتری (Computer vision)، تکنولوژی سازمانی (Enterprise technology)، یادگیری ماشین قابل تفسیر و هوش مصنوعی قابل توضیح (Interpretable ML و XAI).
در این میان، شرکتها با چالشهایی مواجه هستند که توسط تکنولوژی های پیشرفته و به سرعت در حال تکامل قبلی ارائه شده بود. این چالشها شامل اصلاح زیرساختهای قدیمی برای تطبیق با سیستمهای یادگیری ماشین، کاهش تعصبات و پیامدهای مخرب دیگر، و بهینهسازی استفاده از یادگیری ماشین برای تولید سود و در عین حال به حداقل رساندن هزینهها است.
همچنین ملاحظات اخلاقی، حفظ حریم خصوصی داده ها و انطباق با مقررات مسائلی حیاتی هستند که سازمان ها باید با ادغام تکنولوژی های پیشرفته هوش مصنوعی و یادگیری ماشین در عملیات خود به آنها رسیدگی کنند.
سخن آخر
در این مقاله ابتدا تعریفی جامع از یادگیری ماشین (Machine Learning) ارائه شد؛ شاخهای از هوش مصنوعی که تمرکز آن به ساختن سیستمهای کامپیوتری است که از دادهها یاد میگیرند. در ادامه با بررسی مزایا و معایب آن، به معرفی انواع یادگیری ماشین با نمونه های مربوطه میپردازیم و در نهایت نقش انکار ناشدنی یادگیری ماشین در دنیای تکنولوژی آینده بحث شد.
سوالات متداول
یادگیری ماشین (Machine Learning) چیست؟
یادگیری ماشین (Machine Learning) شاخهای از هوش مصنوعی (AI) و علوم کامپیوتر است که بر استفاده از دادهها و الگوریتمها تمرکز میکند تا هوش مصنوعی را قادر سازد تا روش یادگیری انسان را تقلید کند و به تدریج دقت آن را بهبود بخشد.
4 اصل یادگیری ماشین چیست؟
اصول یادگیری ماشین از این قرار هستند: یادگیری تحت نظارت، یادگیری بدون نظارت، یادگیری نیمه نظارتی، یادگیری تقویتی.
تفاوت بین هوش مصنوعی و یادگیری ماشین چیست؟
هوش مصنوعی ایده ماشینی است که بتواند هوش انسان را تقلید کند، در حالی که هدف یادگیری ماشین آموختن نحوه انجام یک کار خاص به ماشین و ارائه نتایج دقیق با شناسایی الگوها است.
آیا ChatGPT هوش مصنوعی است یا یادگیری ماشین؟
ChatGPT شکلی از هوش مصنوعی مولد (generative AI) است؛ ابزاری که به کاربران اجازه می دهد تا با وارد کردن یک پیام، تصویر، متن یا ویدیویی شبیه به انسان دریافت کند که در اصل توسط هوش مصنوعی تولید شده است. ChatGPT مشابه سرویسهای چت خودکار موجود در وبسایتهای خدمات مشتری است، زیرا افراد میتوانند سؤالات خود را از آن بپرسند و یا برای پاسخهای ChatGPT توضیح بخواهند.
در دنیای امروز که امنیت شبکهها و دادهها اهمیت فزایندهای پیدا کرده، انتخاب سیستم عامل مناسب برای مدیریت امنیت و عملکرد شبکهها به یک نیاز اساسی تبدیل شده است. فورتی نت (Fortinet)، یکی از شرکتهای پیشرو در حوزه امنیت سایبری، سیستم عامل FortiOS را به عنوان بخش کلیدی فبریک امنیتی خود توسعه داده است. FortiOS نه تنها به عنوان سیستم عامل اصلی سختافزارهای فورتی نت مورد استفاده قرار میگیرد، بلکه با ارائه قابلیتهای پیشرفتهای مانند همگرایی امنیت و شبکه، هوش مصنوعی، و کنترل جامع بر تمامی اجزا، به یکی از جامعترین پلتفرمهای امنیتی در صنعت تبدیل شده است. در این مطلب، به بررسی جزئیات این سیستم عامل و ویژگیهای آخرین نسخه آن، FortiOS 7.6، میپردازیم تا شما را با امکانات و مزایای این پلتفرم آشنا کنیم.
FortiOS چیست؟
FortiOS یا سیستم عامل فورتی نت (Fortinet’s operating system) پایه و اساس فَبریک (Fabric) امنیتی فورتی نت است. فبریک بر روی یک چارچوب مدیریتی و امنیتی مشترک ساخته شده است و بالاترین عملکرد و گسترده ترین پلت فرم امنیت سایبری صنعت است. FortiOS همگرایی امنیت و شبکه را برای رفع شکاف های امنیتی و ساده سازی مدیریت امکان پذیر می کند. با سیستم عامل فورتی نت، خواهید توانست به تجربه کاربری ثابت، پالِسی های امنیتی مشترک، و دید و کنترل در سراسر محیطها، از جمله زیرساختهای داخلی، ابری، هیبریدی و همگرایی IT/OT/IoT دست پیدا کنید.
ویژگی های FortiOS 7.6
FortiOS 7.6 آخرین به روز رسانی سیستم عامل فورتی نت است که قابلیت ها و خدمات جدیدی را در فَبریک امنیتی فورتی نت به عنوان بالغ ترین و جامع ترین پلتفرم امنیت سایبری موجود در بازار امروز ارائه می کند. آخرین پیشرفتها در FOS 7.6 قابلیتهای جدید یا به روز شدهای را در زمینه های زیر ارائه میکنند:
شبکه ایمن
مؤلفه شبکه ایمن در فَبریک امنیتی فورتی نت ترکیبی از شبکه های حیاتی، اتصال و عملکردهای امنیتی از جمله تکنولوژی عملیاتی، اینترنت اشیا و امنیت لبه است. از جمله پیشرفت های FOS 7.6 در این زمینه می توان از این موارد نام برد:
هوش مصنوعی فورتی (FortiAI) برای مدیریت، تهیه، اسناد و پشتیبانی
سرویس فورتی گیت مدیریت شده
جلوگیری از از دست دادن داده
کنترل دسترسی به شبکه فورتی لینک
کنترل کننده وای فای 7
سرویس های جدید فورتی گارد
SASE یکپارچه
از آنجایی که سازمانها منابع ابری بیشتری را بکار می گیرند و از نیروی کار ترکیبی پشتیبانی می کنند، در نتیجه اهمیت راهکارهای های امنیتی ابری افزایش می یابد. ایمن سازی کاربران راه دور به همراه ارتباطات قابل اعتماد، برای سازمان هایی که استراتژی نیروی کار ترکیبی را برگزیده اند بسیار مهم است. پیشرفت های FortiOS 7.6 در این زمینه می توان به اِیجِنت یکپارچه (فورتی کلاینت) و SASE (SSE + SD-WAN) اشاره کرد. جالب است بدانید، از ادغام SSE و SD-WAN نتایج زیر حاصل می شود:
شناسایی، پیشگیری و اصلاح تهدیدات و حملات همچنان چالشی حیاتی برای بسیاری از تیم های مرکز عملیات امنیتی است. به همین دلیل است قابلیتهای هوش مصنوعی پیشرفته از جمله هوش مصنوعی مولد، برای محیطهای مرکز عملیات امنیتی ایجاد شده تا شناسایی تهدید را تقویت میکند. از پیشرفت های FortiOS 7.6 در این زمینه موارد ذیل هستند:
SOCaaS پیشرفته
ادغام هوش مصنوعی فورتی با فورتی آنالایزر
SIEM Lite
SOAR Lite
حاکمیت، ریسک و انطباق
هوش مصنوعی فورتی (FortiAI) برای واکنش به حوادث امنیتی
ادغام EDR با فورتی کلاینت
مزایای سیستم عامل FortiOS
FortiOS راهکاری موثر برای محافظت از شبکه و زیرساخت فناوری اطلاعات در برابر تهدیدات و حملات اسپم است. با سیستم عامل فورتی نت، کاربران کنترل کاملی بر همه اپلیکیشن ها و سیستمها دارند و می توانند ترافیک ورودی و خروجی به شبکه را به طور موثری مدیریت کنند. هزینه های مقرون به صرفه لایسنس ها در مقایسه با سایر سیستم عامل ها، آن را به یک انتخاب جذاب برای کسب و کارها تبدیل کرده است.
FortiOS با ادغام با فبریک امنیتی فورتی نت یکپارچگی کامل را در کل استقرار سازمان تضمین می کند و به مسائل مختلفی مانند آنتی ویروس، فیلتر DNS، فایروال و جلوگیری از نفوذ می پردازد. سیستم عامل فورتی نت با ارائه گزارشدهی های دقیق و قابلیتهای تحلیلی، کاربران را قادر می سازد تا به عملکرد شبکه نظارت کنند، خطرات امنیتی بالقوه را شناسایی کنند و درباره زیرساختهای خود تصمیم های آگاهانه بگیرند.
فرآیند استقرار این سیستم عامل روان و آسان است و با داشتن گزینه های مختلف قیمتی، یک گزینه ای عملی برای سازمان ها تبدیل شده است. با استفاده از FortiOS، کاربران می توانند دید وسیع تر و دفاع جامع تری در برابر عوامل تهدید داشته باشد تا وضعیت امنیتی خوبی را در سازمان خود داشته باشند.
معایب سیستم عامل FortiOS
از جمله معایبی که برای سیستم عامل فورتی نت گزارش شده پیچیدگی تنظیمات آن است که در شرکت های بزرگتر جدی تر نیز می شود. ارتقا این سیستم عامل و همچنین محدودیت های فیلترینگ URL، دیگر چالش هایی هستند که فراروی کاربران قرار دارند.
سخن پایانی
در مطلب امروز سیستم عامل شرکت فورتی نت بنام FortiOS که مخفف Fortinet’s Operating System است، بررسی شد. این سیستم عامل بر روی سخت افزارهای تولید این شرکت نصب می شود؛ از جمله ویژگی های آخرین نسخه آن یعنی FortiOS 7.6 می توان به این موارد اشاره کرد: پلت فرم SASE با قابلیت های DLP اضافه شده، جداسازی مرورگر راه دور، DEM و عملکردهای دیگر که با ادغام SSE و SD-WAN مرتبط هستند.
سوالات متداول
FortiOS چیست؟
FortiOS یا Fortinet’s Operating System سیستم عامل شبکه فورتی نت است و در هسته فبریک امنیتی فورتی نت قرار دارد؛ با اتصال همه اجزا به یکدیگر، از یکپارچگی دقیق در کل فبریک امنیتی یک سازمان اطمینان حاصل میکند.
کاربرد FortiOS چیست؟
FortiOS همراه با پیشرفتهای فبریک امنیتی فورتی نت، شبکه و مدیریت ایمن، پیشگیری پیشرفته، تشخیص زودهنگام و واکنش به موقع و کاهش خطر را برای سیستمهای کنترل فیزیکی و صنعتی سایبری ارائه میکند.
چه ویژگی های جدیدی در FortiOS 7.6 ارائه شده است؟
از جمله پیشرفت های کلیدی FortiOS 7.6 می توان این موارد را نام برد: ارائه چندین سرویس مدیریتی برای کاهش بار تیمهای NOC و SOC و کاهش نیاز به منابع برای رسیدگی به شکاف مهارتهای امنیت سایبری. فورتی کلاینت دارای عملکرد کامل EDR برای ارائه ZTNA ،EPP و اسکن مداوم آسیبپذیری در یک اِیجنت انفرادی است.
چه دستگاه هایی از FortiOS استفاده می کنند؟
FortiOS که همان سیستم عامل فورتی نت است در سخت افزارهای شرکت فورتی نت مانند فایروال ها و سوئیچ های فورتی گیت استفاده می شود؛ این سیستم عامل مبتنی بر لینوکس است.
امروزه فایروال نسل بعدی (Next Generation Firewall)، موضوع مهمی در دنیای امنیت است زیرا که این فایروال ها علاوه بر ارائه کردن ویژگی ها و قابلیت هایی که فایروالهای قدیمی داشتند، خدمات پیشرفته دیگری را نیز به همراه آن ها عرضه میکنند؛ فایروال های نسل بعدی، علاوه بر اینکه امکان فیلتر ترافیک شبکه را از طریق پورت و پروتکل های یک سیستم تشخیص نفوذ برقرار می کنند، امکان بررسی و آنالیز عمیق بسته ها و… را نیز در اختیار مشتریان قرار می دهند. با ما همراه باشید تا در این مطلب به این موضوع مهم و جدید فایروال ها بپردازیم و در رابطه با خدمات، انواع روش های مستقر سازی و تجهیزات صحبت کنیم.
فایروال نسل بعدی (Next Generation) چیست؟
همانطور که می دانید، فایروال های نسل بعدی یا NGFs، باعث افزایش سطح امنیت شبکه می شوند و برخلاف فایروال قدیمی که فقط قادر هستند ترافیک شبکه را مورد بررسی قرار دهند، فایروال نسل بعدی، طبق قوانین تعیین شده توسط ادمین ها، پورت ها، پروتکل ها و ترافیک شبکه را بر اساس موقعیت و شرایط، بررسی و بلاک میکند؛ جالب است بدانید که فایروال های نسل بعدی از ویژگی های بسیار مهمی برخوردار هستند که در ادامه به برخی از این ویژگی ها میپردازیم:
استفاده کردن از منابع اطلاعاتی خارجی
بررسی و تشخیص انواع بدافزارهای پیشرفته
پیشگیری کردن از نفوذ یکپارچه
بررسی دقیق ترافیک شبکه
شناسایی و بلاک کردن نرم افزار های مشکوک به بدافزار
فیلترینگ محتوای وب
ویژگی های فایروال های نسل بعدی
فایروالهای نسل بعدی (Next-Generation Firewalls یا NGFW) فراتر از فایروالهای قدیمی عمل کرده و امکانات پیشرفتهتری برای محافظت از شبکهها فراهم میکنند. این نوع فایروالها نه تنها ترافیک را بر اساس پورت و پروتکل بررسی میکنند، بلکه لایههای بالاتری از امنیت را نیز ارائه میدهند. در ادامه برخی از امکانات و ویژگیهای اصلی فایروالهای نسل بعدی اشاره می کنیم:
۱- سیستم امنیتی پیشرفته
همانطور که میدانید اولین و مهم ترین وظیفه فایروال های سخت افزاری، جلوگیری کردن از ورود هکر ها و حفظ امنیت شبکه است؛ ولی از آنجایی که اقدامات و عملیات پیشگیرانه همیشه ۱۰۰درصدی نیستند، فایروال نسل بعدی برای افزایش اطمینان، از امکانات و ویژگی های پیشرفته تری جهت شناسایی سریعتر بدافزارها استفاده میکند که سطح امنیت شبکه را به طور چشمگیری افزایش می دهند؛ در ادامه مطلب، به این ویژگی ها و قابلیت های خاص این فایروال ها اشاره می کنیم:
جلوگیری و متوقف کردن حملات،قبل از ورود آن ها به سیستم
استفاده از IPS نسل جدید داخلی جهت شناسایی خطرات و تهدید های مخفی و جلوگیری سریع آن ها از طریق بلاک کردن URL
استفاده از راهکار Sandbox، برای محافظت در برابر بدافزارهای پیشرفته
۲- بلاک کردن تهدید های شبکه:
فایروال های نسل بعدی، از ابزار هایی همچون sandboxing و فیلترینگ URL استفاده می کنند تا از حملات دسترسی به شبکه جلوگیری کنند.
۳- موقعیت جغرافیایی:
فایروال نسل بعدی از طریق ارتباط برقرار کردن بین IP و موقعیت های جغرافیایی مختلف، دسترسی های مبتنی بر مکان یا ترافیک های مستقیم شبکه را محدود سازی میکند.
۴- دید جامع شبکه:
محافظت کردن از شبکه در برابر خطر و تهدیدی که دیده نمی شود، کار بسیار سختی است؛ بنابراین شما همیشه باید ترافیک شبکه خود را کنترل کنید تا خطرات و تهدیدات، به موقع و سریع تشخیص داده شوند و از ورود بدافزار ها و دسترسی های غیر مجاز به شبکه جلوگیری شود؛ همچنین فایروال شما باید یک دیدگاه جامع و کلی از عملکرد شبکه تان داشته باشد تا بتواند مواردی مانند زمان و مکان سازماندهی یک تهدید، انواع اپلیکیشنها و وبسایتهای فعال و فعالیت های تهدیدآمیز در بین کاربران، شبکه ها و دستگاه ها را تشخیص دهد.
۵- تشخیص به موقع حملات شبکه:
شناسایی دقیق و صحیح حملات، کاهش تهدیدات سایبری سیستم ها و شبکه ها و.. از مهم ترین ویژگی های فایروال نسل بعدی به حساب می آیند و این فایروال ها با استفاده از اعتبارسنجی حمله، ترافیک های مخرب شبکه را بلاک می کنند.
۶- قابلیت رمز گشایی آنتی ویروس:
حتی اگر سیستم شما دارای یک راهکار آنتی ویروس (Antivirus Solution) باشد، اما باید توجه داشته باشید که یکی از وظایف اصلی NGFW ها، متوقف کردن حمله، قبل از وارد شدن به شبکه است؛ همین مورد است که باعث تقویت و ساپورت از آنتیویروس سیستم شما شده و سطح امنیت را بالا می برد.
۷- امکان ارائه گزارش وسیع:
فایروال های نسل بعدی گزارش های گسترده و وسیعی را به طور مستقیم در اختیار شما قرار می دهد تا بتوانید از اتفاقات داخلی سیستم به راحتی اطلاع داشته باشید تا در صورت وقوع خطر و تهدید، بتوانید به سرعت به وضعیت امنیتی شبکه خود برشگشته و خطر را رفع کنید.
۸- سریعترین زمان تشخیص:
در حالت عادی، مدت زمان استاندارد تشخیص یک خطر سایبری، ۱۰۰ تا ۲۰۰ روز طول می کشد؛ در حالی که فایروال نسل بعدی آن را طی چند ساعت یا حتی چند دقیقه شناسایی کرده و به شما اعلام می کند تا اقدامات مورد نیاز را در رابطه با خطر پیش آمده تدارک ببینید و به آن رسیدگی کنید.
۹- کنترل هویت کاربران:
یکی از وظایف اصلی فایروال، صدور مجوز به کاربران جهت دسترسی پیدا کردن به شبکه و ردیابی هویت آن ها است؛ در واقع یکی از مهم ترین قسمت های امنیت شبکه، همین موضوع ردیابی کاربران است و فایروال نسل بعدی، فعالیت های کاربران را نظارت می کند و هویت آن ها را از طریق اپلیکیشن های کنترلی از جمله Active Directory بررسی میکند.
۱۰- قابلیت یکپارچگی:
یکی از قابلیت های منحصر به فرد فایروال نسل جدید، قابلیت ادغام شدن با دیگر سیستم های امنیتی است به طوری که فایروال با همکاری کردن با این نرم افزارها، هر مدل نرم افزار مخرب را شناسایی می کند و از شبکه دفاع و محافظت می کند.
چرا باید از فایروال نسل بعدی استفاده کنیم؟
همانطور که میدانید، فایروال ها برای محافظت و تامین امنیت شبکه سایبری مورد استفاده قرار می گیرند و NGFW ها به دلایلی که در زیر به آن ها اشاره کرده ایم، از شبکه محافظت کرده و آن را ایمن نگه میدارند:
وظایف چندین نرمافزار را بهصورت یکجا انجام میدهد.
مقرونبهصرفه است زیرا دیگر نیاز به پرداخت هزینه جداگانه برای تهیه انواع نرم افزار های امنیتی و بهروزرسانی آن ها نخواهد بود.
یک راهکار مدرن برای پشت سر گذاشتن فایروال قدیمی است.
هیچ نوع آسیبی به پهنای باند شبکه وارد نمی کند.
راهکاری یک مرحلهای برای دریافت و حل تمامی مشکلات ایمنی شبکه است.
قابلیت ادغام شدن با سرویسهای هوشمند را دارد.
تفاوت فایروال های نسل بعدی با فایروال های قدیمی
فایروال های نسل بعدی، همان طور که از نام آن ها مشخص است، فایروال های نسل بعدی ورژن پیشرفته تری از فایروال های قدیمی هستند که قابلیت های بیشتری نسبت به فایروال های قدیمی دارند؛ NGFW ها مانند فایروال های قدیمی، از فیلتر های بسته استاتیک و دینامیکی و پشتیبانی از VPN استفاده می کنند تا از معتبر بودن تمامی اتصالات بین شبکه و اینترنت اطمینان حاصل کنند.
هم فایروال قدیمی و هم فایروال نسل بعدی، وظیفه برقراری امنیت شبکه را دارند ولی بین این فایرول ها، تفاوت هایی وجود دارد که اساسی هستند؛ بارز ترین تفاوت، توانایی فیلترینگ تهدید ها است، به طوری که فایروال نسل بعدی از طریق بررسی و آنالیز، اپلیکیشن های ایمن را از اپلیکیشن های ناشناس و مشکوک تشخیص میدهد.
فایروال قدیمی
فایروال نسل بعدی
بررسی Stateful از ترافیک ورودی و خروجی شبکه را انجام می دهند.
علاوه بر بررسی Stateful از ترافیک ورودی و خروجی شبکه، قابلیت های دیگری نیز دارند.
یک سیستم امنیتی کهنه دارد.
دارای راهکار های پیچیدهتری است.
امکان دید و کنترل جزئی دارند.
قابلیت دید و کنترل بیشتری را فراهم میکنند.
روی لایه ۲ و لایه ۴ کار میکند.
روی لایه ۲ تا لایه ۷ کار میکند.
توانایی پشتیبانی از آگاهی در سطح اپلیکیشن کاربردی را ندارد.
آگاهی در سطح اپلیکیشن کاربردی را تسهیل میکند.
از سرویس های اعتباری یا هویتی پشتیبانی نمیکند.
از سرویس های اعتباری یا هویتی پشتیبانی میکند.
نگهداری جداگانهی ابزار امنیتی هزینه بر است.
نصب و پیکربندی تکنولوژیهای امنیتی یکپارچه شده و این، هزینههای مدیریتی را کاهش میدهد.
مجموعهی جامعی از تکنولوژیهای امنیتی فراهم نمی شود.
مجموعهی جامع تری از تکنولوژی های امنیتی فراهم میکند.
نمیتوان ارتباطات SSL را رمزگشایی یا بررسی کرد.
ترافیک SSL از هر دو جهت هم رمزگشایی و هم بررسی می کند.
عملکردهایی همچون ترجمه آدرس شبکه یا NAT، ترجمه آدرس پورت یا PAT و شبکهی خصوصی مجازی یا VPN ارائه می شوند.
قابلیت های ترجمه آدرس شبکه یا NAT، ترجمه آدرس پورت یا PAT و شبکهی خصوصی مجازی یا VPN را بهبود یافته اند و همچنین تکنولوژی های کنترل تهدید جدیدی مانند Sandboxing اضافه شده اند.
سیستم پیشگیری از نفوذ (IPS) یکپارچهسازیشده و سیستم شناسایی نفوذ (IDS)، بهصورت جداگانه پیادهسازی می شوند.
کاملا با سیستم پیشگیری از نفوذ (IPS) و سیستم شناسایی نفوذ (IDS) یکپارچه سازی شده است.
فایروال های نسل بعدی چگونه ارائه می شوند؟
برخلاف بیشتر فایروال های قدیمی، NGFW ها راهی را در اختیار شما قرار داده اند که از طریق آن آپدیت های سرویس را دریافت می کنید؛ فایروال های نسل بعدی از توابع بازرسی پیچیده تری جهت بررسی داده های انتقالی استفاده می کنند که از بازرسی پروتکل و پورت فراتر است و از طریق سرویس های هوشمند، از نفوذ تهدیدها جلوگیری میکنند.
مزایای استفاده از فایروال های نسل بعدی
فایروالهای نسل بعدی (NGFW) مزایای بسیاری را در مقایسه با فایروالهای قدیمی ارائه میدهند که شامل موارد زیر است:
حفاظت چند لایه
در دنیای دیجیتالی امروزی، دیگر یک اپلیکیشن آنتی ویروس ساده که روی موبایل نصب می شود، برای متوقف کردن تهدیدات سایبری کافی نیست و به لایه های حافظتی بیشتری نیازمندیم.
فایروالهای قدیمی شامل قابلیت هایی همچون فیلترینگ Packet ساده، ترجمه کردن آدرس پورت و شبکه، بررسی Stateful و تطبیق پذیری شبکه خصوصی هستند ولی آن ها فقط در Data Link Layer و Transport Layer مدل OSI عمل می کنند و به این لایه های محدود میشوند.
فایروال معمولی با استفاده از اطلاعاتی که از لایه ۴ بدست می آورد و محدود کردن دسترسی پورت ها، امنیت تک لایهای را ارائه می دهد، ولی عملکرد فایروال های نسل بعدی (NGFWs) از این فراتر میرود و ترافیک شبکه را از لایه ۲ تا لایه ۷ از مدل OSI مورد بررسی قرار می دهد؛ این امر برای سازمانها، این قابلیت را فراهم می کند که دید بیشتری به فعالیت های داخل شبکه داشته باشند برای مثال اینکه چه کسی، چه زمانی و از کجا به وب سایت های مخرب دسترسی داشته است.
فایروال های نسل جدید (NGFWs) شامل شناسایی نفوذ، پیشگیری از نفوذ یا IDS/IPS می شوند که حملات را بر اساس آنالیز ترافیک، Signature های خطر یا فعالیت های غیر عادی و مشکوک، شناسایی میکنند.
حفاظت آنتیویروس، باجافزار و اسپم
فایروال نسل جدید (NGFW) برای امن سازی اطلاعات و داده های شرکت، از حفاظت آنتی ویروس، باجافزار و اسپم و امنیت Endpoint می کند که اگر از این ویژگی های فایروال در شبکه سازمان خود استفاده کنید نیاز به ابزار امنیتی دیگری نخواهید داشت.
اینکه فایروال نسل جدید (NGFW) این ویژگی ها و قابلیت ها را دارد، نه تنها در زمان و انرژی سازمان صرفهجویی می کند، بلکه شناسایی و رسیدگی به خطرات و تهدیدات سایبری را نیز تسهیل می کند.
فایروالهای نسل جدید (NGFWs) برخلاف فایروال های قدیمی و کلاسیک، حاوی ضدویروس و ضد بدفزار هستند که هر موقعی که تهدیدات جدیدی صورت بگیرند، به طور خودکار آپدیت میشوند و همچنین با محدود سازی اپلیکیشن هایی که بر روی آن اجرا می شوند، مسیر های حمله را کاهش میدهد.
این دستگاه تمام اپلیکیشن های کاربردی مجاز را مورد بررسی قرار می دهد تا آسیب پذیری های پنهان و مخفی، نقضهای امنیتی داده و همچنین مشکلاتی که توسط اپلیکیشن های کاربردی ناشناس ایجاد می شوند را شناسایی کند؛ این امر به کاهش استفاده پهنای باند توسط ترافیک غیر ضروری مفید است.
قابلیتی برای پیادهسازی دسترسی مبتنی بر نقش
یک راهکار واحد نمی تواند مناسب تمام شرایط و موقعیت ها باشد و در واقع، بسته به نوع کار و عملیات، هر کارمند در یک سازمان به حقوق اینترنتی متفاوتی نیاز دارد؛ برای مثال، کارمندان بخش بازاریابی باید قادر باشند از پلتفرم های رسانه اجتماعی و وب سایت های مختلف استفاده کنند؛ مدیر ارشد IT به اتصال اینترنتی کامل و وسیعی نیاز خواهد داشت، در حالی که مسئولان پذیرش فقط به مراجعان پاسخ می دهند؛ بدین گونه میتوان دسترسی شبکه را با نیازمندی های هر کارمند تطبیق داد.
کنترل Policy پیشرفته
فایروالهای قدیمی و کلاسیک روی مدل ساده تری از پذیرش و عدم پذیرش عمل میکنند و در این الگو، هر کسی با دسترسی به یک اپلیکیشن میتواند از آن استفاده کند و هیچکس به اپلیکیشن کاربردی که ناامن باشد، دسترسی نخواهد داشت؛ که این مدل دیگر کار ساز نیست و در دنیای امروز، یک اپلیکیشن کاربردی که شاید برای شبکه یک سازمان مخرب باشد، بتواند برای سازمان دیگری فوقالعاده مفید و کار ساز باشد. کنترل با دقت و جزئی که توسط فایروال نسل جدید (NGFW) ارائه می شود، باعث می شود که ویژگی های خوب یک اپلیکیشن کاربردی پرسنل مناسب استفاده شوند، در حالی که جوانب منفی یک اپلیکیشن کاربردی بلاک می شوند.
سرعت شبکه
در فایروالهای قدیمی و عادی، هر لایه امنیتی که اضافه شود، احتمال اینکه کل سیستم را دچار مشکل و اختلال کند زیاد است و با وجود وعده های بیهوده فروشندگان فایروال های قدیمی، اگر این اقدامات و عملیاتی امنیتی اجرا شوند، سرعت شبکه کاهش بسیار زیادی پیدا میکند؛ بدون توجه به اینکه آیا خدمات امنیتی ارائه میشوند یا نه و اینکه چه تعدادی دارند، NGFW ها می توانند عملیات با ثباتی را اجرا کنند بدون اینکه نیازی به قربانی کردن سرعت یا کیفیت اتصالات شبکه ای برای دستیابی به امنیت باشد.
زیرساخت ساده
سادگی زیرساخت طراحی شده در فایروال های نسل بعدی، یکی از اصلی ترین مزیت های این فایروال ها است؛ با تسهیل کردن امنیت شبکه، کارمندان IT می توانند با سرعت خیلی بیشتر و فقط از طریق یک دستگاه، استراتژی ها را روی کل شبکه پیاده سازی کنند.
استفاده کردن از معماری های امنیتی پیچیده بسیار کار سخت و دشواری است و کاربران برای رسیدگی کردن به خطرات سایبری، به یک راهکار ساده تری مانند فایروال های نسل جدید نیازمندند؛ این فایروال های جدید که زیرساخت نسبتا ساده تری دارد، به کاربران کمک می کند که در زمان صرفه جویی کنند و در عین حال به فعالیت های روزمرهی شبکه سازمان خود بپردازند. به علاوه، زیرساخت سادهی این فایروال ها به کاربران این امکان را می دهد که پروتکل های امنیتی شبکه را از طریق یک دستگاه واحد مدیریت کنند و آن را ارتقا دهند.
فایروال نسل بعدی چگونه راه اندازی میشود؟
فایروال های نسل بعدی می توانند در لبه شبکه، داخل شبکه، ابر خصوصی و ابر عمومی در شبکه مستقر شوند؛ باید توجه داشته باشید همانقدر که وجود یک فایروال نسل بعدی در شبکه میتواند امنیت سازمان را بسیار تقویت کند، همانقدر نیز میتواند تبدیل به یک موضوع خطرناک شود؛ شاید بپرسید چرا خطرناک؟ که در پاسخ باید بگوییم، اگر یک فایروال نسل بعدی Next Generation Firewall را با درک کاملی از زیرساخت شبکه پیکربندی نکنید فقط می تواند حس کاذبی از امنیت را به شما دهد.
تیمی که فایروال سازمان شما را پیکربندی میکند باید قادر باشد تمام زیرساخت ها را بر روی راهکار NGFW برقرار یا به اصطلاح map کند؛ همچنین شما باید بعد از عمل پیکربندی NGFW، یک دیدگاه کلی و جامع نسبت به شبکه تان داشته باشید. در دنیای امنیت سایبری، وجود یک دید کلی و جامع نسبت به زیرساخت شبکه امری ضروری و حیاتی است که فایروال نسل بعدی این امکان را دارد که بر فعالیت های تمام کاربران تان، هاست های تجهیزات، سرویس ها و کلا به هر جزئی از شبکه نظارت کند؛ ارتباطات شبکه، اپلیکیشن های کاربردی و وب سایت ها از دیگر مواردی هستند که با استفاده از این فایروالها میتوانید بر رویشان نظارت داشته باشید ولی کیفیت در این موارد، ارتباط مستقیمی با چگونگی پیکربندی فایروال دارد.
از فایروال نسل بعدی استفاده کنیم یا خیر؟
نصب و پیکربندی سیستم فایروال برای هر شبکهای چه بزرگ و چه کوچک الزامی است؛ در محیط شبکه های امروزی، مجهز بودن به فایروال نسل بعدی بسیار کمک کننده و ضروری است چرا که نوع و حجم تهدیدها در دستگاه های شخصی و شبکه ها، هر روز در حال تغییر و پیشرفته تر شدن هستند که NGFW ها با انعطافپذیری بالای خود، از سیستم ها و شرکت ها در برابر طیف گسترده تری از نفوذها و خطرات محافظت میکنند.
جمع بندی
نصب یک فایروال نسل بعدی آنقدر ساده است که میتواند فقط با چند کلیک صورت بگیرد ولی این کافی نبوده و حتی میتواند خطرناک نیز باشد؛ شرکت داریا، میتواند در این زمینه خدمات بسیاری را در اختیار شما قرار دهند و علاوه بر خرید NGFW با مناسب ترین قیمت، خدمات نصب و پشتیبانی نیز دارد.
همانگونه که به مرور زمان اپلیکیشن های تجاری به محیط های ابری و محلی تبدیل می شوند، کاربران نیازمند یک دسترسی ایمن و بدون محدودیت جغرافیایی هستند؛ در اینجا، دیگر فایروال های قدیمی کارساز نیستند چرا که یک محیط شبکه ای منفرد، به چندین میکرو محیط تبدیل شده است. در تکامل محیط های کار ترکیبی، اپلیکیشن ها، محیط جدیدی برای بسیاری از سازمان ها محسوب می شوند. فایروال های قدیمی، شامل مجموعه ای از ابزار های فیزیکی، مجازی و ابری است که باعث می شود سازمان ها در عملیات مرتبط به محیط های کاربردی، دچار مشکل شوند. در ادامه این مطلب با ما همراه باشید.
فایروال برند سیسکو (Cisco)
شرکت سیسکو، یک کمپانی ارائه دهنده تجهیزات امنیت شبکه است و یک رویکرد خودکار، چابک و یکپارچه را برای هماهنگی در اجرای سیاست در اپلیکیشن های مدرن و شبکه های ناهمگن فراهم کرده است؛ فایروال های سیسکو (Cisco Secure Firewall)، عمیق ترین مجموعه ادغامی در عملکرد های شبکه و امنیت شبکه هستند که امنیت را برای شرکت ها و سازمان های حساس فراهم می کند.
در واقع، سیسکو یک مجموعه امنیتی کامل و بهینه ای ارائه می دهد که از اپلیکیشن ها و کاربران، در هر زمان و در هر مکانی محافظت می کند؛ این خدمات، مناسب انواع کسب و کار ها است که مشاغل کوچک و متوسط تا مراکز داده سازمانی را شامل می شود.
مزایای فایروال های سیسکو
فایروال های سیسکو از مزایای بیشماری برای شبکه های سازمانی برخوردارند که در ادامه به اصلی ترین و جدید ترین آن ها می پردازیم:
عملیات ساده
با وجود بسیاری از گزینه های مدیریتی، روابط گردش کار، بازنگری شده و هوش مصنوعی امنیتی جدید، به این سیستم اضافه شده است؛ بنابراین می توان گفت مدیریت ساده تر از همیشه است.
کنترل های امنیتی ویژه
تشخیص تهدیدات رمزگذاری شده بدون رمزگشایی ترافیک، با استفاده از تکنولوژی تشخیص تهدید تالوس و سایر ویژگی های فایروال سیسکو میسر شده است.
سازگار با بودجه
فایروال ها و سایر تجهیزات امنیت شبکه شرکت سیسکو با بهترین کیفیت و لایسنس، با مناسب ترین قیمت عرضه می شوند. شما می توانید برای اطلاعات بیشتر در رابطه با انتخاب و خرید انواع فایروال های سیسکو و سایر تجهیزات امنیت شبکه با کارشناسان مجرب شرکت داریا تماس حاصل کنید.
چرا باید فایروال سیسکو را انتخاب کنیم؟
فایروال های سیسکو، در مقایسه با فایروال های دیگر، امنیت بیشتری را در برابر تهدیدات پیچیده سایبری ارائه می دهند که شما با استفاده از آن می توانید از کسب و کار و سرمایه خود محافظت کنید؛ شما با سرمایه گذاری روی تجهیزات سیسکو، روی پایه امنیت سایبری شبکه خود سرمایه گذاری می کنید که هم چابک و یکپارچه است و هم قوی ترین وضعیت امنیتی را در سراسر شبکه برقرار می سازد.
فایروال سیسکو (Cisco)، بدون اینکه عملکرد بازرسی ترافیک رمزگذاری شده را مختل کند، محافظت قدرتمندی را در برابر گسترده ترین و پیچیده ترین خطرات و تهدیدات سایبری ارئه می دهد و ادغام آن با سایر راهکار های Cisco و شخص ثالث، یک مجموعه گسترده و عمیقی از محصولات امنیتی را در اختیار سازمان ها قرار می دهد که حوادث سایبری گذشته را جبران می کند و با حذف نویز و جلوگیری از تهدیدات، عملکرد کلی شبکه را به طور چشمگیری بهبود می بخشد.
دید و کنترل برتر
همانطور که می دانید، شبکه ها گسترده تر و تهدیدات سایبری پیچیده تر شده اند و تعداد بسیار کمی از سازمان ها موفق به دفع همه تهدیدات سایبری و همچنین به روز نگه داشتن خود به طور مداوم می شوند.
با پیچیده تر شدن تهدیدات سایبری، اهمیت داشتن ابزار و تجهیزات مناسب برای محافظت از داده ها و اپلیکیشن های شبکه سازمانی نیز افزایش یافته است؛ فایروال های سیسکو، از قدرت و انعطاف پذیری بالایی برخوردار هستند که همیشه شما را یک قدم جلوتر از حملات سایبری قرار می دهند.
فایروال امن سیسکو، با داشتن سخت افزار پرسرعت، ترافیک رمزگشایی شده و ترافیک رمزگشایی نشده را بررسی می کند که این قابلیت باعث می شود، شما عملکرد فایروال شبکه خود را به طرز چشمگیری ارتقا دهید.
علاوه بر این موارد، سیاست قابل فهم بودن قوانین (human-readable rules) باعث شده است که موضوع امنیت به موضع ساده تری تبدیل شود؛ همچنین قابلیت مشاهده و کنترل اپلیکیشن از طریق ادغام Cisco Secure Workload ارائه شده است که به محافظت مداوم از اپلیکیشن های مدرن امروزی در سراسر شبکه کمک می کند.
مدیریت ساده فایروال
شرکت سیسکو، گزینه های مدیریتی انعطاف پذیری را برای مدیریت چندین فایروال از یک مکان مرکزی ارائه می دهد که شما می توانید به روش های مختلف، عملکرد و بهره وری شبکه سازمانی خود را افزایش دهید و از کیفیت و قدرت بالای این خدمات برخوردار شوید؛ با راهکار ارائه شده در فضای ابری نیز می توانید کارایی شبکه خود را حتی به مقدار بیشتری افزایش دهید.
کدام فایروال سیسکو برای کسب و کار شما مناسب است؟
شرکت سیسکو، فایروال های مختلفی را با قابلیت های متفاوتی عرضه می کند که این ویژگی ها هستند که تعیین کننده ی مناسب بودن یک فایروال برای نیاز های کسب و کار شما هستند؛ برای انتخاب و خرید مناسب ترین فایروال که با نیاز های سازمان شما سازگار باشد، نیاز است که از یک کارشناس مجرب در این زمینه کمک بگیرید؛ برای این منظور، می توانید با کارشناسان شرکت داریا تماس بگیرید.
قیمت فایروال سیسکو
فایروال های سیسکو در سری های مختلف که از ویژگی های مختلفی برخوردارند، عرضه می شوند، قیمت های متفاوتی دارند؛ با این حال، شرکت داریا وارد کننده معتبر تجهیزات امنیت شبکه است که فایروال های سیسکو را با مناسب ترین قیمت در اختیار مشتریان خود قرار می دهد؛ شما می توانید جهت دریافت مشاوره رایگان و اطلاع از قیمت دقیق فایروال ها، با کارشناسان ما تماس بگیرید.
خرید فایروال سیسکو
با وجود کلاهبرداری های زیادی که در رابطه با خرید و فروش تجهیزات امنیت شبکه رخ می دهد، بسیار مهم است که در خرید فایروال شبکه خود دقت کنید و آن را از یک فروشنده معتبر خریداری کنید؛ شرکت داریا، وارد کننده و عرضه کننده معتبر تجهیزات امنیت شبکه از جمله فایروال سیسکو است که شما می توانید جهت دریافت مشاوره و خرید انواع فایروال های سیسکو، سوفوس، فورتی گیت با کارشناسان شرکت داریا تماس بگیرید.
جمع بندی
در پایان، باید بدانید که با افزایش گستردگی و پیچیدگی خطرات و حملات سایبری، بسیار مهم است که شبکه سازمان شما دارای یک فایروال قدرتمند باشد که قادر است از شبکه شما در برابر هر نوع حمله سایبری محافظت کند. به این ترتیب بهترین راهکار در این زمینه انتخاب و خرید بهترین فایروال های سیسکو با کمک کارشناسان مجرب در این زمینه است.
سیسکو ISE به عنوان یک محصول جدید، طیف وسیعی از راه حل ها و خدمات امنیتی را در یک مجموعه یکپارچه ارائه می دهد. در این مطلب تلاش داریم شما را به صورت کامل با سیسکو ISE آشنا کرده و مزیت های آن را به طور جامع و کامل توضیح دهیم؛ در ادامه این مطلب با ما همراه باشد.
Cisco ISE چیست؟
سیسکو ISE یا Cisco Identity Services Engine یک نسل جدید از سیستم های شناسایی و کنترل دسترسی است که به شبکه ها این امکان را می دهد، به سادگی سرویس دهی کرده و وضعیت امنیتی زیرساخت خود را ارتقا دهند. در واقع سیسکو ISE یک پلتفرم مدیریت خط مشی امنیتی است که دسترسی ایمن به منابع و داده های شبکه را فراهم می کند؛ به بیان دیگر، این پلتفرم به عنوان مرکزی برای تصمیم گیری در مورد سایت ها عمل می کند تا شرکت ها از تطابق با این سیاست ها، زیرساخت های امنیت شبکه را ساده سازی کرده و خدمات رسانی را تقویت کنند.
سیسکو ISE چگونه کار می کند؟
این سیستم برای تصمیم گیری در مورد مجاز بودن دسترسی کاربران و اینکه چه سطح دسترسی به هر یک از آن داده شود، به سیاست های شبکه استناد می کند. در واقع، هنگامی که یک دستگاه به شبکه متصل می شود، سیسکو ISE هویت کاربر را، به همراه نوع دستگاهی که از آن استفاده می کند، زمان و مکان درخواست کاربر و روش دسترسی مورد استفاده را، بررسی می کند؛ پس از تایید درخواست توسط سیسکو ISE، دسترسی به شبکه برای کاربر فراهم می شود.
Cisco ISE چگونه کار می کند؟
Cisco ISE به عنوان یک پلتفرم مدیریت سیاست امنیتی متمرکز عمل می کند و کنترل دسترسی و عملیات امنیتی را برای شبکه های سیمی و بی سیم ساده می کند. در ادامه خلاصه ای از نحوه عملکرد و کاربردهای اصلی آن آورده شده است:
احراز هویت: هنگامی که یک کاربر یا دستگاه تلاش می کند به شبکه متصل شود، Cisco ISE یک فرآیند احراز هویت را انجام می دهد.
احراز دسترسی: سیسکو ISE پس از احراز هویت، سطح دسترسی کاربر یا دستگاه را تعیین می کند. این تصمیم بر اساس سیاست های امنیتی از پیش تعریف شده است که عواملی مانند هویت کاربر، نوع دستگاه، موقعیت مکانی و وضعیت امنیتی دستگاه را در نظر می گیرد.
پروفایل سازی: Cisco ISE به طور مداوم داده های مربوط به دستگاه های موجود در شبکه را نظارت و جمع آوری می کند. این پروفایل آن را قادر می سازد تا دستگاه ها را تشخیص دهد، تطابق آن ها را با سیاست های امنیتی ارزیابی کند و کنترل های دسترسی را در صورت لزوم تطبیق دهد.
مدیریت مهمان: Cisco ISE یک فرآیند ساده برای دسترسی مهمان فراهم میکند و به بازدیدکنندگان این امکان را میدهد تا به طور ایمن و طبق سیاستهای دسترسی تعیین شده توسط سازمان به شبکه متصل شوند.
کاهش تهدید: با راه حل های امنیتی دیگر برای شناسایی و پاسخ سریع به تهدیدات ادغام می شود. اگر دستگاهی در معرض خطر قرار گیرد، Cisco ISE میتواند آن را قرنطینه کند و گسترش تهدیدات بالقوه را محدود کند.
کاربرد Cisco ISE
از انواع کاربرد های سیسکو ISE می توان به موارد زیر اشاره کرد:
اطمینان حاصل می کند که فقط کاربران مجاز و دستگاه های سازگار می توانند به منابع شبکه دسترسی داشته باشند و از داده های حساس محافظت می کنند.
با اجرای سیاستهای امنیتی کنترل دسترسی، به سازمانها کمک میکند تا از مقررات صنعت پیروی کنند.
مدیریت خط مشی های دسترسی را در اتصالات سیمی، بی سیم و VPN ساده می کند و پیچیدگی را کاهش می دهد.
برای تصمیمگیری آگاهانه و کنترلهای امنیتی دقیقتر، دید جامعی را در اتصالات شبکه ارائه میدهد.
با سایر سیستم های امنیتی ادغام می شود تا پاسخ به تهدیدات را خودکار کند و وضعیت امنیتی را بهبود بخشد.
ویژگی های مهم Cisco ISE
سیسکو ISE دارای ویژگی های متعددی است که در ادامه به آنها اشاره می کنیم:
سیسکو ISE برای مدیریت Authorization،Authentication و Accounting از پروتکل RADIUS استفاده می کنند. این پروتکل به ISE اجازه می دهد تا تمامی فرآیند های تایید هویت، مجوزدهی و حسابداری را به شکل متمرکز و امن مدیریت کند.
پروتکل احراز هویت
سیسکو ISE از پروتکل های متنوعی برای تایید هویت پشتیبانی می کند. این پروتکل ها شامل، MS-CHAP، PAP، EAP-FAST، PEAP، EAP-TLS و EAP-MD5 می باشند، که هرکدام برای نیاز های امنیتی مختلف و قابل استفاده استفاده هستند.
اکسس کنترل
ISE از مجموعه گسترده ای از مکانیزم های کنترل دسترسی ارائه می دهد؛ از جمله این مکانیزم ها VILAN، URL Redirect، Assignment و SGA tagging هستند.
وضعیت
با استفاده از سیسکو ISE ،WEB Agent وضعیت دستگاه هایی که به شبکه متصل می شوند مورد بررسی قرار می گیرند. مدیران شبکه می توانند معیار های مختلفی مانند وضعیت آنتی ویروس، به روزرسانی سیستم عامل و دیگر معیارهای امنیتی را برای این بررسی ها تعیین کنند.
مدل خط مشی
مدل سیاست های ISE این امکان را فراهم می کند که با استفاده از قوانین مختلف، کنترل دسترسی انعطاف پذیری داشته باشیم. این سیستم به مدیران اجازه می دهد تا به صورت دقیق تر و سفارشی، دسترسی ها را مدیریت کنند.
مدیریت مهمان
این ویژگی به شما اجازه می دهد تا در سیسکو ISE کاربرانی با دسترسی محدود ایجاد کنید و از آن ها برای مدیریت کاربران مهمان استفاده نمایید. این قابلیت به خصوص در محیط هایی با تردد زیاد کاربران مهمان مفید است.
ویژگی های مهم Cisco ISE
از جمله مزایای سیسکو ISE می توان به موارد زیر اشاره کرد:
اطلاعات متمرکز: داده ها را از منابع مختلف احراز هویت جمع آوری می کند و نیاز به ارتباط هر سیستم با هر منبع احراز هویت را از بین می برد.
عملکرد بهبود یافته: با استفاده از یک سیستم واحد که داده ها را برای سایر مصرف کنندگان داده های احراز هویت ذخیره می کند، بار اضافی را از زیرساخت هایی که اغلب بیش از حد استفاده می شوند، حذف می کند.
پشتیبانی از سرور Syslog: داده های احراز هویت را از سیستم هایی که از Syslog پشتیبانی می کنند، جمع آوری می کند.
اندپوینت: متوجه می شود که چه زمانی دستگاه ها از سیستم خارج می شوند.
پشتیبانی از APIهای سفارشی: داده های احراز هویت را از سیستم هایی که رابط های سفارشی پشتیبانی می کنند، جمع آوری می کند.
سخن پایانی
در این مطلب به صورت کامل و جامع با سیسکو ISE آشنا شدیم. آگاهی شما در این حوزه می تواند به شما در حفظ امنیت سازمان بسیار کمک کننده باشد. شرکت داریا وارد کننده انواع دستگاه های امنیت شبکه است؛ برای کسب اطلاعات بیشتر با کارشناسان مجرب داریا تماس حاصل فرمایید.
سوالات متداول
دستگاه ISE چیست؟
یک پلت فرم مدیریت خط مشی امنیتی که دسترسی ایمن به شبکه را برای کاربران و دستگاه ها فراهم می کند
چرا از ISE استفاده کنیم؟
ISE به شما این امکان را می دهد که دسترسی شبکه ای بسیار امن را برای کاربران و دستگاه های مختلف فراهم کنید
آیا Cisco ISE یک NAC است؟
سختافزار سیسکو در حوزه شبکههای سازمانی نسبتاً محبوب است، بنابراین راه حل سیسکو یکی از پیشروها در فضای NAC است.
XSS یکی از 10 حمله امنیتی رایج است که سازمان ها و شرکت هایی که با برنامه های کاربردی تحت وب سر و کار دارند را مورد هدف قرار می دهند. در این مطلب با این نوع حمله آشنا می شویم و انواع آن را مورد بررسی قرار می دهیم و با راه های جلوگیری از آن را آموزش می دهیم. در ادامه این مطلب با داریا همراه باشید.
حمله XSS چیست؟
حمله XSS یا Cross_Site Scriptingیک نوع رایج از حمله تزریق کد است که برنامه های تحت وب را با تشخیص آسیب پذیری آن ها و تزریق کد مخرب، مورد هدف قرار می دهد. در این حمله مهاجم یک کد مخرب را به وبسایت می فرستد و زمانی که کاربران برای بارگذاری وبسایت اقدام می کنند، کد به صورت خودکار اجرا می شود. معمولا، این کد به انتهای یک آدرس URL اضافه شده و یا مستقیما در صفحه ای که محتوا در آن قرار دارد، جاسازی می شود.
انواع حمله XSS
حملات XSS به سه دسته تقسیم می شوند که از جمله این حملات می توان به موارد زیر اشاره کرد:
XSS ذخیره شده
XSS های ذخیره شده مخرب ترین نوع آسیب پذیری است؛ این حمله زمانی رخ می دهد که اطلاعت مخرب ارائه شده توسط مهاجم در سرور ذخیره شود، این داده خطرناک دائما در معرض صفحه وب قرار می گیرد و هنگامی که کاربر عملیات مرور معمولی را انجام می دهد فعال می شود.
XSS منعکس شده
این نوع از آسیب پذیری XSS زمانی اتفاق می افتد که داده های ارائه شده توسط کاربران، معمولا از طریق پارامتر های درخواست HTTPS در صفحه بدون فیلتر یا ذخیره مناسب، نمایش داده میشود.
XSS بر اساس DOM
حملات XSS بر اساس DOM یا Document Object Model یک نوع از آسیب پذیری بین سایت ها است و هنگامی رخ می دهد که جاوا اسکریپت، داده ها را از منبع کنترل شده مهاجم دریافت کرده و برای تغییر و اصلاح به محیط DOM ارسال می کند؛ این باعث می شود مرورگر قربانی به طور غیر منتظره اجرا شود.
یک مهاجم به وسیله XSS چه کاری می تواند انجام دهد؟
هکر ها و مهاجمان سایبریی که از Cross_Site Scripting استفاده می کنند، قادر به انجام رفتارهای زیر با قربانیان خود هستند:
جعل هویت کاربر قربانی شده.
انجام هر کاری که کاربر قادر به انجام آن است.
مشاهده تمام اطلاعاتی که کاربر به آن ها دسترسی دارد.
حمله XSS جاوا اسکریپت بین هکر ها و مهاجمان بسیار محبوب است؛ به دلیل اینکه جاوا اسکریپت به برخی از داده های حساس دسترسی دارد و می توان از این دسترسی برای سرقت اطلاعات اکانت و اهداف مجرمانه دیگر استفاده کرد. فرایند یک حمله معمولی XSS به صورت زیر است:
در مرحله اول قربانی، صفحه وب را بارگذاری کرده و کد مخرب، به کپی کردن کوکی های مخرب می پردازد.
کد مخرب، یک درخواست HTTP را همراه با کوکی های دزدیده شده در بدنه ی درخواست، به وب سرور مهاجم ارسال می کند.
و در آخر، مهاجم می تواند از این کوکی ها برای جعل هویت کاربر قربانی استفاده کرده و اطلاعات حساب های بانکی، اطلاعات اکانت و سایر اطلاعات حساس به سرقت می برد.
چرا باگ XSS خطرناک است؟
این باگ به راحتی می تواند اطلاعات اکانت و پسورد های شما را بدزدد؛ یا اگر در یک سایتی که نسبت به حملات XSS آسیب پذیر باشد، اطلاعت اکانت خود را وارد کنید، مهاجم می تواند کد مخربی را در سایت تزریق کرده و اطلاعات شما را به سرقت ببرد و از آن سوء استفاده کند.
آسیب های ناشی از Cross_Site Scripting
تاثیر اصلی XSS عموما به ساختار برنامه، اطلاعات و وضعیت کاربری که در معرض خطر قرار دارد بستگی دارد. به عنوان مثال:
در یک برنامه تبلیغاتی، که در آن همه ی کاربران ناشناس هستند و تمام اطلاعات عمومی هستند، تاثیر اغلب کم تر خواهد بود.
در برنامه هایی که اطلاعات حساس و مهمی مانند تراکنش های بانکی، ایمیل ها و سوابق بیمه را نگه داری می کنند، آسیب، عموما بسیار بیشتر و جدی تر خواهد بود.
نحوه مقابله با حملات XSS
برای مقابله با این نوع حمله نمیتوانیم از یک راه کار برای انواع مختلف این حمله استفاده کنیم؛ بلکه باید از روش ها و راهکار های کاربردی مختلف برای جلوگیری از این حمله استفاده کنیم؛ چرا که انواع مختلف برنامه های کاربردی وب، به سطوح امنیتی مختلفی نیاز دارند. در ادامه چند مورد از مهم ترین اقدامات امنیتی برای جلوگیری از این حملات را معرفی می کنیم.
از HTML در فیلد های ورودی خودداری کنید
یکی از راه های موثر برای جلوگیری از این نوع حملات این است که مانع از ارسال HTML در ورودی های فرم ها توسط کاربران شوید. انتخاب های دیگری هم وجود دارند که به کاربران اجازه می دهند بدون استفاده از HTML، یک محتوای خوب ایجاد کنند.
اعتبارسنجی ورودی ها
با استفاده از اعتبارسنجی، کاربر نمی تواند در فرمی که از استاندارد های خاصی پیروی نمی کند، داده ای ارسال کند. قوانین اعتبار سنجی می تواند به گونه ای تنظیم شوند که تگ ها و کاراکتر هایی مانند <script> که در XSS استفاده می شوند را رد کنند.
پاکسازی داده
پاکسازی داده ها، مشابه اعتبارسنجی انجام می شود؛ با این تفاوت که پس از ارسال داده ها در وب سرور و قبل نمایش آن ها برای کاربران دیگر، اتفاق می افتد. ابزار های آنلاین مختلفی برای پاکسازی HTML و فیلتر کردن تزریق کد مخرب وجود دارند.
فیلتر کردن ورودی ها
فیلتر کردن باید در مکانی که ورودی های کاربر دریافت می شوند، بر اساس داده هایی که انتظارشان را دارد، تا حد ممکن دقیق انجام شود.
مرورگر امن
مرورگر هایی مانند Firefox و Opera امنیت بالاتری نسبت به IE دارند؛ IE مرورگری است که نقاط ضعف زیادی دارد.
برای جلوگیری از این نوع حمله می توان ایمیل را روی حالت HTML یا متنی قرار داد تا کد های مخرب خود به خود اجرا نشوند. بهتر است کاربران گزینه ذخیره اطلاعات اکانت و پسورد های خود را در مرورگرها غیر فعال کنند و به صورت دوره ای، رمز عبور ایمیل های خود را تغییر دهند. همچنین بهتر است کاربران از ایمیل های مجزا برای حساب های کاربری مهم خود مانند حساب بانکی و … استفاده کنند و از آن برای کار های روزانه خود استفاده نکنند.
Escaping
در این روش اطلاعات ورودی توسط کاربر فیلتر یا سانسور می شود. مثلا از ثبت بعضی از کاراکترهای خاص مانند > و < که ممکن است در دستورات کد استفاده شوند جلوگیری می شود و باعث می شوند که کد های مخرب از کار بیفتند.
تنظیم قوانی WAF
یک فایروال اپلیکیشن وب، می تواند برای جلوگیری از حملات XSS بازتابی تنظیم شود. این قوانین از ارسال درخواست های نامناسب به سرور، از جمله حملات XSS جلوگیری می کنند.
سخن پایانی
حملات XSS با اینکه می توانند برای هر سایتی بسیار خطرناک باشند و تمامی کاربران سایت را مورد حمله قرار دهند، به راحتی هم قابل پیشگیری هستند. آگاهی کافی از این نوع حمله ها می تواند به شما کمک کند تا مورد حمله مهاجمان سایبری قرار نگیرید و از اطلاعات و داده ها به شیوه بهتری محافظت کنید.
سوالات متداول
آیا حملات XSS مربوط به خود کاربر می شود؟
اگر شخصی با استفاده از حمله XSS به صورت خودسرانه اسکریپت های مخرب جاوا را روی سایت شما اجرا کند، امنیت وب سایت شما پایین آمده و در معرض خطر قرار می گیرد.
یک مثال واقعی از حملات XSS به چه صورت است؟
یک گروه از مهاجمان سابری از یک آسیب پذیری XSS در یک کتابخانه جاوا اسکریپت به نام Feedify که در وب سایت British Airway استفاده می شد، سوء استفاده کردند.
آنتی ویروس XSS چیست؟
Avast One به متوقف کردن XSS در مسیرهای خود کمک می کند، بنابراین نگران این که اطلاعاتتان در معرض خطر هکر باشد، نباشید.
XSS در شبکه چیست؟
XSS یک سوء استفاده است که در آن مهاجم کد را به یک وب سایت قانونی متصل می کند و زمانی که قربانی وب سایت را بارگذاری می کند اجرا می شود.
امنیت اپلیکیشن با هدف محافظت از کد و داده های اپلیکیشن در برابر خطرات و تهدیدات سایبری طراحی شده است؛ هر سازمان، باید از راهکار امنیت اپلیکیشن در تمامی مراحل توسعه کسب و کار خود از جمله طراحی، توسعه و استقرار استفاده کند. در ادامه این مطلب با شرکت ارائه دهنده تجهیزات امنیت شبکه داریا همراه باشید.
مفهوم امنیت اپلیکیشن
امنیت اپلیکیشن را می توان پروسه توسعه، افزایش و آزمایش ویژگی ها و قابلیت های امنیتی اپلیکیشن ها در نظر گرفت؛ که به منظور جلوگیری از آسیب پذیری های امنیتی سایبری و تهدیداتی همچون دسترسی ها و دستکاری های غیر مجاز صورت می گیرد.
امنیت اپلیکیشن چیست؟
امنیت اپلیکیشن، راهکاری است که اقدامات امنیتی را در سطح اپلیکیشن پیاده سازی می کند تا از سرقت و ربوده شدن داده ها و کد های درون برنامه جلوگیری شود؛ این اقدامات، شامل ملاحظات امنیتی، در طول طراحی و توسعه اپلیکیشن و همچنین سیستم ها و رویکرد حفاظتی اپلیکیشن ها می شود.
امنیت اپلیکیشن شامل سخت افزارها، نرم افزارها و شیوه هایی می شود که آسیب پذیری های امنیتی را شناسایی و آن ها را به حداقل می رساند؛ جالب است بدانید روتری که آدرس IP کامپیوتر شما را مخفی می کند، نوعی امنیت اپلیکیشن سخت افزاری محسوب می شود.
توجه داشته باشید که اقدامات امنیتی سطح اپلیکیشن، معمولا در نرم افزار تعبیه می شوند؛ برای مثال، می توان به یک فایروال اپلیکیشن که دقیقا فعالیت های مجاز و غیر مجاز سازمانی را مشخص می کند اشاره کرد. همچنین بهتر است بدانید که این شیوه های تشخیص و کاهش آسیب پذیری سایبری، شامل مواردی مانند روال امنیتی اپلیکیشن و پروتکل هایی از جمله آزمایش متداول (regular testing) است.
چرا تامین امنیت اپلیکیشن مهم است؟
امروزه، امنیت اپلیکیشن از اهمیت بالایی برخوردار است چرا که اپلیکیشن های امروزی، از طریق شبکه های مختلف قابل دسترسی هستند که همین امر، آسیب پذیری ها و نقض های امنیتی را در برابر تهدیدات و نقض های امنیتی افزایش می دهد.
جالب است بدانید، امروزه با استقبال چشمگیری برای تامین امنیت در سطح شبکه و درون اپلیکیشن ها مواجه هستیم که یکی از دلایل آن این است که هکر ها بیشتر از گذشته، اپلیکیشن ها را مورد هدف حملات خود قرار می دهند؛ شما با تست کردن امنیت اپلیکیشن های خود می توانید نقاط ضعف اپلیکیشن ها را شناسایی کرده و از حملات سایبری پیشگیری کنید.
انواع امنیت اپلیکیشن
امنیت اپلیکیشن دارای انواع مختلفی است که شامل احراز هویت، احراز دسترسی، رمزگذاری، ورود به سیستم و تست امنیت اپلیکیشن میشود؛ همچنین توسعه دهندگان می توانند برای کاهش آسیب پذیری های امنیتی، اپلیکیشن ها را کد گذاری کنند.
احراز هویت
همانطور که گفته شد، توسعه دهندگان شیوه ای را برای اطمینان از دسترسی کاربران مجاز به اپلیکیشن ها پیش می گیرند؛ این شیوه، احراز هویت نام دارد؛ این کار با درخواست ارائه نام کاربری و پسورد از کاربر، هنگام ورود به اپلیکیشن صورت می گیرد.
توجه داشته باشید که در احراز هویت چند عاملی، هنگام ورود به اپلیکیشن، کاربر به چند روش مختلف احراز هویت می کند؛ برای مثال، یک احراز هویت چند عاملی می تواند شامل یک پسورد، تلفن همراه شخصی، اثر انگشت یا تشخیص چهره باشد.
احراز دسترسی
پس از احراز هویت، معمولا احراز دسترسی نیز به صورت خودکار صورت می گیرد تا کاربر، مجاز به استفاده از اپلیکیشن باشد؛ این کار با مقایسه هویت کاربر با لیستی از کاربران مجاز توسط سیستم صورت می گیرد که در صورت تایید، کاربر مجاز به استفاده از منابع اپلیکیشن خواهد بود. توجه داشته باشید که احراز هویت باید قبل از احراز دسترسی انجام شود تا اپلیکیشن اطلاعات اکانت کاربر را با لیست کاربران مجاز تطبیق دهد.
رمزگذاری
وقتی که کاربر احراز هویت کرده و در حال استفاده از اپلیکیشن است، سایر اقدامات امنیتی نیز صورت می گیرد که از داده های حساس، در برابر دیده شدن و استفاده شدن توسط مجرمان سایبری محافظت می کنند؛ در اپلیکیشن های مبتنی بر ابر، داده های حساس رمزگذاری می شوند تا در مسیر حرکتشان، از فاش شدن و دستکاری جلوگیری شود.
لاگین (log in)
در صورت وجود یک حادثه امنیتی در یک اپلیکیشن، لاگین یا ورود به سیستم، می تواند مشخص کند که چه کسی، در چه زمانی، به چه اطلاعاتی دسترسی پیدا کرده است؛ فایل های لاگ اپلیکیشن، یک گزارش، با مهر زمانی ارائه می دهد که مشخص می کند چه کسی، به کدام جنبه های اپلیکیشن و در چه زمانی دسترسی داشته است.
تست امنیت اپلیکیشن
تست امنیت اپلیکیشن، یک پروسه ضروری است که از عملکرد درست کنترل های امنیتی اطمینان حاصل می کند.
امنیت اپلیکیشن در فضای ابری
جالب است بدانید که امنیت اپلیکیشن در فضای ابری، با چالش های بیشتری همراه است و از آنجایی که فضاهای ابری شامل منابع اشتراکی هستند، باید مطمئن شد که کاربران فقط به داده هایی دسترسی دارند که مجاز به آن هستند؛ همچنین باید توجه داشته باشید که داده های حساس در اپلیکیشن های مبتنی بر ابر، آسیب پذیرتر هستند چرا که این داده ها در سراسر اینترنت، از کاربر به اپلیکیشن و برعکس، منتقل می شوند.
امنیت اپلیکیشن موبایل
گوشی های موبایل، برخلاف شبکه های خصوصی، اطلاعات را از طریق اینترنت ارسال و دریافت می کنند که این امر، آن ها را در برابر حملات سایبری، آسیب پذیر می کند؛ سازمان ها می توانند از شبکه های خصوصی مجازی یا همان VPN ها، برای ایجاد یک لایه حفاظتی برای اپلیکیشن های موبایل کاربران استفاده کنند.
بخش های IT سازمان ممکن است اپلیکیشن های موبایل کاربران را مورد بررسی قرار دهند و قبل از صدور مجوز استفاده از آن ها، از مطابقت آن ها با سیاست های امنیتی سازمان اطمینان حاصل کنند.
امنیت وب اپلیکیشن ها
امنیت وب اپلیکیشن ها، برای اپلیکیشن های کاربردی اعمال می شود که شامل اپلیکیشن ها و سرویس هایی می شود که کاربران از طریق رابط مرورگر و از طریق اینترنت به آن ها دسترسی دارند؛ از آنجایی که وب اپلیکیشن ها بجای قرار گیری در سیستم کاربر، بر روی سرور های از راه دور مستقر می شوند، داده ها بایستی از طریق اینترنت منتقل شود.
امنیت اپلیکیشن های کاربردی وب، برای ارائه دهندگان وب اپلیکیشن و سرویس وب، بسیار مورد توجه است چرا که این کسب و کار ها با استفاده از فایروال وب اپلیکیشن (WAF)، از شبکه خود در برابر نفوذ های غیرمجاز محافظت می کنند؛ فایروال وب اپلیکیشن (WAF)، بسته های داده ای را بررسی می کند و در صورت مشاهده موارد مشکوک، آن ها را بلاک می کند.
کنترل های امنیتی اپلیکیشن چیست؟
کنترل های امنیتی اپلیکیشن، شامل تکنیک هایی برای افزایش امنیت یک اپلیکیشن در سطح کد نویسی می شود که آسیب پذیری های اپلیکیشن را در برابر تهدیدات سایبری کاهش می دهد؛ این کنترل ها معمولا در رابطه با نحوه پاسخ دهی اپلیکیشن به ورود های غیرمنتظره یک مجرم سایبری است؛ یک برنامه نویس می تواند طوری برای یک اپلیکیشن کدنویسی کند که خود برنامه نویس، کنترل بیشتری بر این ورود های غیرمنتظره داشته باشد.
Fuzzing، یک نوع تست امنیت اپلیکیشن است که در آن، توسعه دهندگان نتیجه ورود های غیرمنتظره و موارد دیگر را آزمایش و بررسی می کنند تا دریابند اپلیکیشن، در چه موقعیت هایی رفتار نادرستی از خود نشان میدهد و از بوجود آمدن حفره های امنیتی جلوگیری کنند.
جمع بندی
در پایان، بهتر است بدانید که همه ی اپلیکیشن های کاربردی و مورد استفاده کاربران، نیاز به حداقل میزانی از حفاظت و امنیت دارند که این هم به دلیل افزایش و پیشرفت خطرات و تهدیدات سایبری است که مهاجمان سایبری با گذشت زمان، اپلیکیشن ها را بیشتر مورد هدف حملات خود قرار می دهند.
سوالات متداول
لایه امنیتی اپلیکیشن چیست؟
لایه امنیت اپلیکیشن یک بخش مهم از استراتژی امنیت سایبری سازمان است که با توجه به اینکه لایه اپلیکیشن در معرض کاربران و اینترنت قرار می گیرد، به یک دفاع تخصصی و قدرتمند در برابر طیف وسیعی از تهدیدات نیازمند است.
چرا باید از امنیت اپلیکیشن استفاده کنیم؟
استفاده از امنیت اپلیکیشن از اهمیت بالایی برخوردار است چرا که اپلیکیشن ها معمولا یک نقطه ورود اولیه به سیستم ها یا داده های حساس برای مهاجمان سایبری محسوب می شوند.
مدل امنیتی اپلیکیشن چیست؟
امنیت اپلیکیشن مجموعه ای از ابزارها، شیوه ها و سیاست هایی است که برای محافظت از لایه اپلیکیشن در برابر تهدیدات استفاده می شود.
احتمالاً هنگام تنظیم پورت فورواردینگ در روتر یا هنگام پیکربندی نرم افزار فایروال، ارجاعاتی به TCP و UDP دیده اید؛ این دو پروتکل برای انواع مختلف داده ها استفاده می شود. TCP/IP مجموعه ای از پروتکل هایی است که توسط دستگاه ها برای برقراری ارتباط از طریق اینترنت و اکثر شبکه های محلی استفاده می شود. این نام از دو پروتکل اصلی آن، پروتکل کنترل انتقال (TCP) و پروتکل اینترنت (IP) گرفته شده است. TCP راهی را برای ارائه و دریافت جریان بسته های اطلاعاتی ترتیب دار و بررسی شده از لحاظ خطا، در شبکه به اپها ارائه می دهد. پروتکل دیتاگرام کاربر (UDP) توسط اپها برای ارائه جریان سریعتری از اطلاعات با حذف بررسی خطا استفاده میشود. هنگام پیکربندی برخی از سخت افزارها یا نرم افزارهای شبکه، ممکن است لازم باشد تفاوت را بدانید.
پروتکل UDP چیست؟
پروتکل UDP (User Datagram Protocol) یکی از پروتکلهای اصلی لایه انتقال در مدل TCP/IP است که برای انتقال سریع دادهها بین دستگاههای شبکه استفاده میشود. UDP یک پروتکل بدون اتصال است، به این معنی که پیش از ارسال دادهها، نیازی به برقراری و حفظ ارتباط پایدار بین فرستنده و گیرنده وجود ندارد. این پروتکل به دادهها به صورت بستههای مستقل (Datagram) نگاه میکند و هیچ کنترلی بر ترتیب، تکرار یا از دست رفتن بستهها ندارد. بر خلاف TCP که برای تضمین تحویل دادهها از تکنیکهایی مانند شمارهگذاری و تأیید دریافت استفاده میکند، UDP این وظایف را به عهده نمیگیرد و به همین دلیل به عنوان یک پروتکل غیرمطمئن شناخته میشود.
به دلیل همین ساختار ساده و بدون سربار، UDP از سرعت بالایی برخوردار است و برای برنامههای حساس به زمان که نیازمند تاخیر کم هستند، بسیار مناسب است. کاربردهای UDP شامل پخش زنده ویدئو، گیمهای آنلاین و پروتکلهای پرسوجو مانند DNS است که در آنها سرعت انتقال مهمتر از اطمینان کامل به تحویل بستهها است. با این حال، به دلیل عدم ارائه کنترل خطا، در شرایطی که دادههای حیاتی انتقال مییابند، استفاده از UDP ریسک بیشتری دارد و در صورت لزوم، راهکارهای دیگری مانند ارسال مجدد دادهها باید در لایههای بالاتر اعمال شوند.
پروتکل TCP چیست؟
پروتکل TCP (Transmission Control Protocol) یکی از پروتکلهای اصلی لایه انتقال در مدل TCP/IP است که برای انتقال دادههای مطمئن بین دستگاههای شبکه استفاده میشود. TCP یک پروتکل اتصالمحور است، به این معنا که قبل از انتقال دادهها، ابتدا یک ارتباط پایدار بین فرستنده و گیرنده برقرار میکند. این پروتکل تضمین میکند که تمام بستههای داده به صورت صحیح و بدون خطا به مقصد میرسند، حتی اگر شبکه دارای نویز یا از دست دادن بستهها باشد. TCP از شمارهگذاری بستهها، تأیید دریافت و کنترل جریان استفاده میکند تا دادهها را به ترتیب و به طور کامل به گیرنده برساند.
TCP برای برنامههایی که به انتقال دقیق و اطمینان از تحویل دادهها نیاز دارند، مانند وبگردی (HTTP/HTTPS)، ارسال ایمیل (SMTP) و انتقال فایل (FTP)، مناسب است. به دلیل مکانیزمهای کنترل خطا و تضمین تحویل، TCP نسبت به پروتکلهای سبکتر مانند UDP، دارای سربار بیشتری است و ممکن است کمی کندتر عمل کند، اما امنیت و قابلیت اطمینان بالاتری در ارسال دادهها فراهم میکند.
مقایسه پروتکل های TCP و UDP
در اینجا مقایسه پروتکلهای TCP و UDP را به صورت کامل و تخصصی برایتان آورده ایم:
نوع اتصال:
TCP: اتصالگرا (Connection-Oriented) – ابتدا ارتباطی پایدار بین مبدأ و مقصد ایجاد میشود.
UDP: غیراتصالگرا (Connectionless) – بدون نیاز به ایجاد ارتباط اولیه، دادهها مستقیماً ارسال میشوند.
روش انتقال دادهها:
TCP: دادهها به صورت جریانی و متوالی ارسال میشوند و ترتیب تحویل دادهها تضمین میشود.
UDP: دادهها به صورت پکتهای جداگانه ارسال میشوند و ترتیب تحویل آنها تضمینی نیست.
مکانیزم اطمینان از تحویل:
TCP: از Acknowledgment (تأیید دریافت) استفاده میکند تا مطمئن شود پکتها به مقصد رسیدهاند و در صورت بروز خطا، پکتها دوباره ارسال میشوند.
UDP: هیچ تأییدی دریافت نمیشود و در صورت بروز خطا، پکتها حذف میشوند و دوباره ارسال نمیگردند.
سرعت:
TCP: به دلیل مکانیزمهای بررسی و کنترل، کندتر از UDP است.
UDP: سریعتر است زیرا هیچ مکانیسم کنترلی پیچیدهای ندارد.
سایز هدر:
TCP: هدر 20 بایت است که شامل اطلاعات بیشتری برای کنترل ارتباط میباشد.
UDP: هدر 8 بایت است و بسیار سادهتر است.
کاربردها:
TCP: برای وبگردی (HTTP/HTTPS)، انتقال فایل (FTP) و ایمیل (SMTP) که نیاز به اطمینان و دقت در انتقال دادهها دارند.
UDP: برای استریم ویدئو، بازیهای آنلاین و پروتکلهای DNS که نیاز به سرعت بالا و تاخیر کم دارند.
کنترل جریان و ازدحام:
TCP: از کنترل جریان و کنترل ازدحام استفاده میکند تا از پر شدن بیش از حد شبکه جلوگیری کند.
UDP: هیچ مکانیزمی برای کنترل جریان یا ازدحام ندارد.
شباهت پروتکل های TCP و UDP
TCP و UDP، هر دو پروتکلهایی هستند که برای ارسال بیتهای داده معروف به بستهها از طریق اینترنت استفاده میشوند. هر دو پروتکل بر روی پروتکل IP ساخته می شوند. به عبارت دیگر، چه شما یک بسته را از طریق TCP ارسال کنید و یا UDP، آن بسته به یک آدرس IP ارسال می شود. همانطور که از کامپیوتر شما به روترهای واسطه و به مقصد ارسال می شوند، با این بسته ها به طور مشابه رفتار می شود. TCP و UDP تنها پروتکل هایی نیستند که در بالای IP کار می کنند. با این حال، آنها بیشترین استفاده را دارند.
نحوه کار پروتکل TCP
TCP رایج ترین پروتکل مورد استفاده در اینترنت است. وقتی یک صفحه وب را در مرورگر خود درخواست می کنید، کامپیوتر شما بسته های TCP را به آدرس وب سرور ارسال می کند و از آن می خواهد که صفحه وب را برای شما ارسال کند. وب سرور با ارسال جریانی از بستههای TCP پاسخ میدهد که مرورگر وب شما آنها را به یکدیگر متصل میکند تا صفحه وب را تشکیل دهند. وقتی روی لینکی کلیک میکنید، وارد سیستم میشوید، نظر ارسال میکنید یا هر کار دیگری انجام میدهید، مرورگر وب شما بستههای TCP را به سرور ارسال میکند و سرور بستههای TCP را پس میفرستد.
در TCP همه چیز در مورد اطمینان است بسته های ارسال شده با TCP ردیابی می شوند تا هیچ داده ای در حین انتقال از بین نرود یا خراب شود. به همین دلیل است که دانلود فایلها خراب نمیشود، حتی اگر مشکل شبکه وجود داشته باشد. البته، اگر سیستم دیگر کاملاً آفلاین باشد، کامپیوتر شما تسلیم میشود و پیام خطایی خواهید دید که نمیتواند با میزبان راه دور ارتباط برقرار کند.
TCP از دو طریق به این امر دست می یابد. ابتدا بسته ها را با شماره گذاری آنها مرتب می دهد. دوم، با فرستادن پاسخی از گیرنده به فرستنده که نشان می دهد پیام را دریافت کرده است، خطا را بررسی می کند. اگر فرستنده پاسخ درستی دریافت نکند، میتواند بستهها را دوباره ارسال کند تا اطمینان حاصل شود که گیرنده، آن ها را به درستی دریافت کرده است. Process Explorer و سایر ابزارهای سیستمی میتوانند نوع ارتباطات یک پروسس را نشان دهند در اینجا میتوانیم مرورگر کروم را با ارتباطات TCP باز به سرورهای مختلف وب مشاهده کنیم.
UDP چگونه کار می کند؟
پروتکل UDP مشابه TCP کار می کند، اما تمام موارد بررسی خطا را حذف می کند. تمام ارتباطات رفت و برگشتی باعث ایجاد تأخیر می شود و سرعت را کاهش می دهد. هنگامی که یک اپ از UDP استفاده می کند، بسته ها فقط برای گیرنده ارسال می شوند. فرستنده منتظر نمی ماند تا مطمئن شود گیرنده بسته را دریافت کرده است – فقط به ارسال بسته های بعدی ادامه می دهد. اگر گیرنده چند بسته UDP را اینجا و آنجا از دست بدهد، آنها فقط گم شده اند، فرستنده آن ها را دوباره ارسال نمی کند. از دست دادن این همه هزینه به این معنی است که دستگاهها میتوانند سریع تر با هم ارتباط برقرار کنند.
UDP زمانی استفاده می شود که سرعت، مطلوب باشد و اصلاح خطا ضروری نباشد. به عنوان مثال، UDP اغلب برای پخش زنده و بازی های آنلاین استفاده می شود. به عنوان مثال، فرض کنید در حال تماشای یک جریان ویدیویی زنده هستید که اغلب با استفاده از UDP به جای TCP پخش می شود. سرور فقط یک جریان ثابت از بسته های UDP را به کامپیوترهایی که در حال تماشا هستند ارسال می کند. اگر برای چند ثانیه ارتباط خود را از دست بدهید، ویدیو ممکن است برای لحظه ای ثابت یا جهش کند و سپس به بیت فعلی پخش پرش کند. اگر با از دست دادن بسته های جزئی مواجه شدید، ویدیو یا صدا ممکن است برای لحظه ای کج و کوله شود در حالی که ویدیو بدون داده های از دست رفته به پخش ادامه می دهد.
این در بازی های آنلاین نیز مشابه است. اگر برخی از بستههای UDP را از دست دادید، با دریافت بستههای UDP جدیدتر، ممکن است کاراکترها به آن طرف نقشه تلپورت شوند. اگر بسته های قدیمی را از دست دادید، هیچ فایده ای ندارد که آنها را دوباره درخواست بکنید زیرا بازی بدون شما ادامه می یابد. تنها چیزی که مهم است این است که در حال حاضر در سرور بازی چه اتفاقی می افتد، نه اتفاقی که چند ثانیه پیش رخ داده است. حذف تصحیح خطای TCP به سرعت بخشیدن به ارتباط بازی و کاهش تأخیر کمک می کند.
بهتر است بدانید اینکه یک برنامه از TCP یا UDP استفاده می کند به توسعه دهنده آن بستگی دارد و انتخاب، بستگی به نیازهای یک اپلیکیشن دارد. اکثر اپها به تصحیح خطا و قدرت TCP نیاز دارند، اما برخی از اپلیکیشن ها به سرعت و کاهش سربار UDP نیاز دارند. اگر یک ابزار آنالیز شبکه مانند وایرشارک را راه اندازی کنید، می توانید انواع مختلف بسته هایی را که به رفت و آمد می کنند را مشاهده کنید.
مگر اینکه مدیر شبکه یا توسعهدهنده نرمافزار باشید، این نباید خیلی روی شما تأثیر بگذارد. اگر روتر یا نرمافزار فایروال خود را پیکربندی میکنید و مطمئن نیستید که یک اپلیکیشن از TCP یا UDP استفاده میکند، به طور کلی میتوانید گزینه “هر دو” را انتخاب کنید تا روتر یا فایروال شما قوانین یکسانی را برای ترافیک TCP و UDP اعمال کند.
سخن پایانی
در نهایت، انتخاب بین پروتکلهای TCP و UDP به نیازهای خاص هر برنامه و نوع دادهای که منتقل میشود بستگی دارد. TCP با ارائه اطمینان و کنترل خطا، برای برنامههایی که نیاز به دقت و امنیت در انتقال دادهها دارند، مانند وبگردی و انتقال فایل، ایدهآل است. از سوی دیگر، UDP به خاطر سرعت بالا و تأخیر کم، برای برنامههایی مانند پخش زنده و بازیهای آنلاین مناسبتر است، جایی که سرعت بر دقت اولویت دارد. با توجه به این تفاوتها، توسعهدهندگان باید بر اساس نوع کاربرد و ویژگیهای مورد نیاز، پروتکل مناسب را انتخاب کنند تا بهترین عملکرد و تجربه کاربری را فراهم آورند.